


![]()
Support



Feel free to send me suggestions on how to improve this. I would be delighted to learn more!! You can also feel free to assign issues here. Run the unit tests as well to learn how the project works!
Important Developer Note!
When using Neuron it operates about 10X faster when you run with a RELEASE scheme. This is due to the compiler optimizations being set to the highest optimization value. If you find Neuron is running somewhat slowly this might be a reason why.
Before you begin developing
Run ./scripts/onboard.sh to install the Xcode templates that Neuron provides to quickly generate layer code templates.
Grand Re-Opening!
Version 2.0 of Neuron is here! This new version of Neuron is a complete rewrite from the ground up of the architecture. It is much more streamlined, with faster execution. Its usage also aligns more with commonly used ML frameworks like Keras and PyTorch.
Background
Neuron has been a pet project of mine for years now. I set off to learn the basics of ML and I figured the best way to learn it was to implement it myself. I decided on Swift because it was the language I knew the most and I knew it would be challenging to optimize for ML as it has a lot of overhead. What you're seeing here in this repository is an accumulation of my work over the past 2 years or so. It is my baby. I decided to make this open source as I wanted to share what I've learned with the ML and Swift community. I wanted to give users of this framework the opportunity to learn and implement ML in their projects or apps. Have fun!
There is still a lot missing in this framework but with this rewrite I brought a lot more flexibity to the framework to allow for playing around with different architectures and models. There are some example models provided with the framework, like Classifier, GAN, WGAN, and WGANGP. I am always working on this project and will continue to provide updates.
Examples
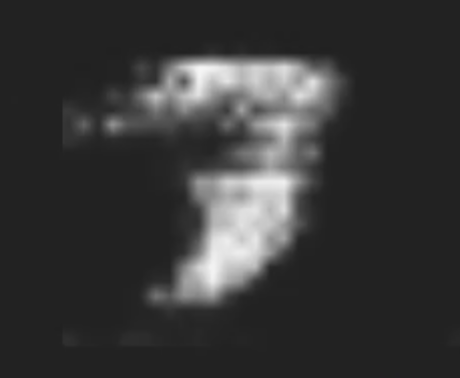
GAN, WGAN, WGANGP
Generated 7's from a WGAN. Trained on MNIST 7's for 10 epochs. 16 - 32 kernels on the generator.


Contribution Policies
Filing Issues
Feel free to file issues about the framework here or contact me through the Discord. I am open to all suggestions on how to improve the framework.
Pull Requests
There are automated tests that run when a PR is created to the develop or master branches. These tests must pass before a PR can be merged. All PRs must merge into the develop branch.
Branching
All features must be branched off the develop branch.
Important Note: GPU Support (WIP)
Currently there is no GPU execution, at least not as how I would like it. Everything runs on the CPU, with some C optimizations for certain mathematical functions. Neuron will run multithreaded on the CPU with somewhat decent speed depending on the model. However a very large model with serveral kernels and convolutions will take a while. This is something I want to get working ASAP however Metal is very difficult to work with, especially with my limited knowledge and my desire to write everything from scratch.
Quick Start Guide
To get started with Neuron it all begins with setting up a Sequential object. This object is responsible for organizing the forward and backward passes through the network.
Build a Network
Let's build an MNIST classifier network. We need to build a Sequential object to handle our layers.
let network = Sequential {
[
Conv2d(filterCount: 16,
inputSize: TensorSize(array: [28,28,1]),
padding: .same,
initializer: initializer),
BatchNormalize(),
LeakyReLu(limit: 0.2),
MaxPool(),
Conv2d(filterCount: 32,
padding: .same,
initializer: initializer),
BatchNormalize(),
LeakyReLu(limit: 0.2),
Dropout(0.5),
MaxPool(),
Flatten(),
Dense(64, initializer: initializer),
LeakyReLu(limit: 0.2),
Dense(10, initializer: initializer),
Softmax()
]
}
Sequential takes in one property which is block that returns an array of Layer types. init(_ layers: () -> [Layer]). The order here matters. The first layer is a Conv2d layer with 16 filters, padding .same, and an initializer. The default initializer is .heNormal.
First layer note:
You can see here the first layer is the only layer where the inputSize is specified. This is because all the other layer's inputSize are automatically calculated when added to an Optimizer.
Picking an Optimizer
Neuron uses a protocol that defines what's needed for an Opitmizer. There are currently three provided optimizers bundled with Neuron.
AdamSGDRMSProp
All optimizers are interchangeable. Optimizers are the "brain" of the network. All function calls to train the network should be called through your specific Optimizer. Let's build an Adam optimizer for this classifier.
let optim = Adam(network,
learningRate: 0.0001,
l2Normalize: false)
The first parameter here is the network we defined above. learningRate is the the size of the steps the optimizer will take when .step() is called. l2Normalize defines if the optimizer will normalize the gradients before they are applied to the weights. Default value for this is false. Adam also takes in properties for its beta1, beta2, and epsilon properties.
Decay Functions
An Optimizer has an optional property for setting a learning rate decay function.
public protocol DecayFunction {
var decayedLearningRate: Float { get }
func reset()
func step()
}
Currently there's only one available DecayFunction and that's ExponentialDecay. You can set a decay function by setting the decayFunction property on the Optimizer. Once it's set there's nothing else that needs to be done. The Optimizer with take care of updating and calling the function object.
Set up training model
By this point you are ready to train the Optimizer and the network. You could create your own training cycle to create the classifier or you can use the built in provided Classifier model.
The Classifier model is a completely optional class that does a lot of the heavy lifting for you when training the network. Let's use that for now.
let classifier = Classifier(optimizer: optim,
epochs: 10,
batchSize: 32,
threadWorkers: 8,
log: false)
Here we create a Classifier object. We pass in the Adam Optimizer we defined earlier, the number of epochs to train for, the batch size, and the number of multi-threaded workers to use. 8 or 16 is usually a good enough number for this. This will split the batch up over multiple threads allowing for faster exectution.
Building the MNIST dataset
NOTE: Be sure to import NeuronDatasets to get the MNIST and other datasets.
Next step to get the MNIST dataset. Neuron provides this locally to you through the MNIST() object.
let data = await MNIST().build()
We can use the Async/Await build function for simplicity. Datasets also support Combine publishers.
Time to train!
To train the network using the Classifier object just call classifier.fit(data.training, data.val). That's it! The Classifier will now train for the specified number of epochs and report to the MetricProvider if set.
Retrieving Metrics
All Optimizers support the addition of a MetricsReporter object. This object will track all metrics you ask it to during the initialization. If the metric isn't supported by your netowrk setup it will report a 0.
let reporter = MetricsReporter(frequency: 1,
metricsToGather: [.loss,
.accuracy,
.valAccuracy,
.valLoss])
optim.metricsReporter = reporter
optim.metricsReporter?.receive = { metrics in
let accuracy = metrics[.accuracy] ?? 0
let loss = metrics[.loss] ?? 0
//let valLoss = metrics[.valLoss] ?? 0
print("training -> ", "loss: ", loss, "accuracy: ", accuracy)
}
The metricsToGather array is a Set of Metric definitions.
public enum Metric: String {
case loss = "Training Loss"
case accuracy = "Accuracy"
case valLoss = "Validation Loss"
case generatorLoss = "Generator Loss"
case criticLoss = "Critic Loss"
case gradientPenalty = "Gradient Penalty"
case realImageLoss = "Real Image Loss"
case fakeImageLoss = "Fake Image Loss"
case valAccuracy = "Validation Accuracy"
}
MetricReporter will call receive when it is updated.
Remote metric logging
You can use the NeuronRemoteLogger to log to remote services like Weights and Biases. Follow the instructions in the README in that repo on how to get started!
Exporting your model
Once the model has trained to your liking you can export the model to a .smodel file. This model cvan be then imported later using the Sequential intializer. The export will not export your Optimizer settings, only the Trainable specified in the Optimizer.
Neuron provides a helper object for exporting called ExportHelper. The usage is simple:
// defined:
public static func getModel<T: Codable>(filename: String = "model", model: T) -> URL?
// usage:
ExportHelper.export(filename: "my_model", model: network)
This will return a URL for you to access your .smodel file.
Pretty-print your network
You can also print your network to the console by calling print on the Sequential object. It will pretty print your network as below:
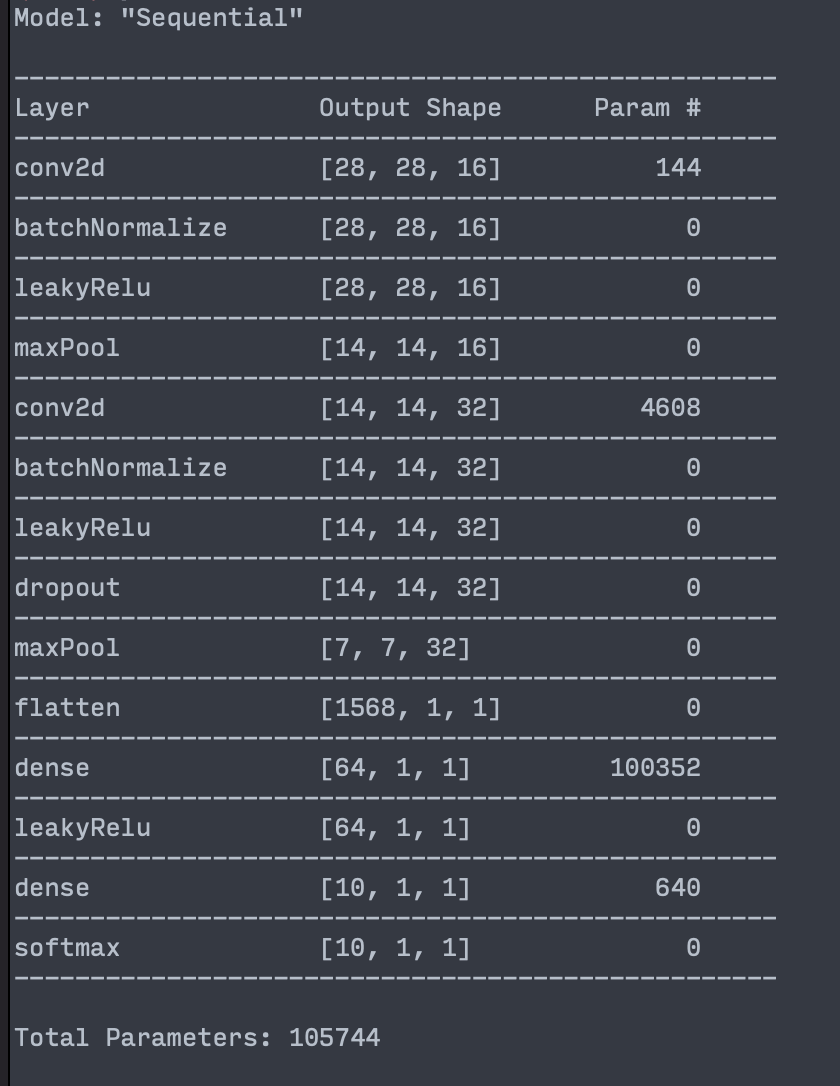
Finishing up
Keep playing around with your new model and enjoy the network! Share your model on the Discord or ask for some other models that others have made!
Basics Background
How does Neuron work?
Tensor
The main backbone of Neuron is the Tensor object. This object is basically a glorified 3D array of numbers. All Tensor objects are 3D arrays however they can contain any type of array in-between. Its size is defined by a TensorSize object defining columns, rows, depth.
public class Tensor: Equatable, Codable {
...
public init() {
self.value = []
self.context = TensorContext()
}
public init(_ data: Scalar? = nil, context: TensorContext = TensorContext()) {
if let data = data {
self.value = [[[data]]]
} else {
self.value = []
}
self.context = context
}
public init(_ data: [Scalar], context: TensorContext = TensorContext()) {
self.value = [[data]]
self.context = context
}
public init(_ data: [[Scalar]], context: TensorContext = TensorContext()) {
self.value = [data]
self.context = context
}
public init(_ data: Data, context: TensorContext = TensorContext()) {
self.value = data
self.context = context
}
}
Above are the initializers that Tensor supports. More in-depth documentation on Tensor can be found here.
Arithmetic
You can perform basic arithmetic opterations directly to a Tensor object as well.
static func * (Tensor, Tensor.Scalar) -> Tensor
static func * (Tensor, Tensor) -> Tensor
static func + (Tensor, Tensor) -> Tensor
static func + (Tensor, Tensor.Scalar) -> Tensor
static func - (Tensor, Tensor.Scalar) -> Tensor
static func - (Tensor, Tensor) -> Tensor
static func / (Tensor, Tensor.Scalar) -> Tensor
static func / (Tensor, Tensor) -> Tensor
static func == (Tensor, Tensor) -> Bool
Building a backpropagation graph
You can attach a Tensor to another Tensor's graph by calling setGraph(_ tensor: Tensor) on the Tensor whose graph you'd like to set.
let inputTensor = Tensor([1,2,3,4])
var outputTensor = Tensor([2])
outputTensor.setGraph(inputTensor)
Doing so will set the inputTensor as the graph to the outputTensor. This means that when calling .gradients on the outputTensor the operation will look as such:
delta -> outputTensor.context(inputTensor) -> gradients w.r.t to inputTensor
Unless you're building a graph yourself or doing something custom, you'll never have to set a graph yourself. This will be handled by the Sequential object.
Gradients
More in-depth TensorContext documentation can be found here.
Neuron performs gradient descent operations using Tensor objects and their accompanying TensorContext.
Tensor objects contain an internal property called context which is of type TensorContext. TensorContext is an object that contains the backpropagtion information for that given Tensor. As of right now Neuron doesn't have a full auto-grad setup yet however Tensor objects with their TensorContext provides some type of auto-grad.
public struct TensorContext: Codable {
public typealias TensorBackpropResult = (input: Tensor, weight: Tensor)
public typealias TensorContextFunction = (_ inputs: Tensor, _ gradient: Tensor) -> TensorBackpropResult
var backpropagate: TensorContextFunction
public init(backpropagate: TensorContextFunction? = nil) {
let defaultFunction = { (input: Tensor, gradient: Tensor) in
return (Tensor(gradient.value), Tensor())
}
self.backpropagate = backpropagate ?? defaultFunction
}
public func encode(to encoder: Encoder) throws {}
public init(from decoder: Decoder) throws {
self = TensorContext()
}
}
When calling .gradients(delta: SomeTensor) on a Tensor that has an attached graph it wil automatically backpropagate all the way through the graph and return a Tensor.Gradient object.
public struct Gradient {
let input: [Tensor]
let weights: [Tensor]
let biases: [Tensor]
public init(input: [Tensor] = [],
weights: [Tensor] = [],
biases: [Tensor] = []) {
self.input = input
self.weights = weights
self.biases = biases
}
}
A Tensor.Gradient object will contain all the gradients you'll need to perform a backpropagation step in the Optimizer. This object contains gradients w.r.t the input, w.r.t the weights, and w.r.t the biases of the graph.
GitHub
| link |
| Stars: 69 |
| Last commit: 19 hours ago |
Dependencies
Related Packages
Release Notes
What's Changed
- Fix memory leak by @wvabrinskas in https://github.com/wvabrinskas/Neuron/pull/68
Full Changelog: https://github.com/wvabrinskas/Neuron/compare/2.0.16...2.0.17
Swiftpack is being maintained by Petr Pavlik | @ptrpavlik | @swiftpackco | API | Analytics