The markdown parsing is broken/disabled for release notes. Sorry about that, I'm chasing the source of a crash that's been bringing this website down for the last couple of days.
## Overview
Many small incremental updates + Token level timestamps with DTW by @denersc in https://github.com/ggerganov/whisper.cpp/pull/1485
Feedback is welcome!
**Full Changelog**: https://github.com/ggerganov/whisper.cpp/compare/v1.5.4...v1.5.5
## What's Changed
* server : fix server temperature + add temperature_inc by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1729
* main : add cli option to disable system prints by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1740
* server: add request path by @eschmidbauer in https://github.com/ggerganov/whisper.cpp/pull/1741
* Optional Piper TTS support for talk-llama example. by @RhinoDevel in https://github.com/ggerganov/whisper.cpp/pull/1749
* fix/1748 by @nank1ro in https://github.com/ggerganov/whisper.cpp/pull/1750
* Don't compute timestamps when not printing them. by @ghindle in https://github.com/ggerganov/whisper.cpp/pull/1755
* Add more parameters to server api by @ghindle in https://github.com/ggerganov/whisper.cpp/pull/1754
* Add SetInitialPrompt method to go bindings by @blib in https://github.com/ggerganov/whisper.cpp/pull/1753
* ggml : fix 32-bit ARM compat for IQ2_XS by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1758
* refactor: get all scripts to be POSIX Compliant by @sonphantrung in https://github.com/ggerganov/whisper.cpp/pull/1725
* whisper : load the model into multiple buffers of max size 1GB by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1763
* rebase against your -np changes (thx) and add better python file to be used on the command line or as library by @contractorwolf in https://github.com/ggerganov/whisper.cpp/pull/1744
* examples/talk-llama: Add optional commandline parameter to set the bot name. by @RhinoDevel in https://github.com/ggerganov/whisper.cpp/pull/1764
* server : fix building and simplify lib deps on Windows by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1772
* talk-llama: optional wake-up command and audio confirmation by @Rakksor in https://github.com/ggerganov/whisper.cpp/pull/1765
* examples/server: implement "verbose_json" format with token details by @rmmh in https://github.com/ggerganov/whisper.cpp/pull/1781
* whisper.android: Return output from benchmarks by @luciferous in https://github.com/ggerganov/whisper.cpp/pull/1785
* libwhisper.so should be position independent by @trixirt in https://github.com/ggerganov/whisper.cpp/pull/1792
* Docs: try to make model options / model install methods clearer by @mrienstra in https://github.com/ggerganov/whisper.cpp/pull/1806
* common : fix input buffer check by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1812
* Update Makefile by @jwijffels in https://github.com/ggerganov/whisper.cpp/pull/1813
* Add fields to `verbose_json` response and show examples on the home page by @JacobLinCool in https://github.com/ggerganov/whisper.cpp/pull/1802
* common: fix wav buffer detection by @JacobLinCool in https://github.com/ggerganov/whisper.cpp/pull/1819
* Add macOS deployment target option to Makefile by @didzis in https://github.com/ggerganov/whisper.cpp/pull/1839
* Expose CUDA device setting in public API by @didzis in https://github.com/ggerganov/whisper.cpp/pull/1840
* whisper.android: How to build with CLBlast by @luciferous in https://github.com/ggerganov/whisper.cpp/pull/1809
* server: Allow CORS request with authorization headers by @valenting in https://github.com/ggerganov/whisper.cpp/pull/1850
* Embed Metal library source into compiled binary by @didzis in https://github.com/ggerganov/whisper.cpp/pull/1842
* added audio_ctx argument to main and server examples by @dscripka in https://github.com/ggerganov/whisper.cpp/pull/1857
* whisper : fix external encoder by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1860
* swift : package no longer use ggml dependency by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1861
* fix openvino setup docs by @jumpers775 in https://github.com/ggerganov/whisper.cpp/pull/1874
* clean up common code in examples by @felrock in https://github.com/ggerganov/whisper.cpp/pull/1871
* main : check if input files exist before proceeding by @Theldus in https://github.com/ggerganov/whisper.cpp/pull/1872
* Linking issue fix via Makefile when CUBLAS enabled in the WSL #1876 by @lbluep in https://github.com/ggerganov/whisper.cpp/pull/1878
* main : fix file existence check in main.cpp by @Theldus in https://github.com/ggerganov/whisper.cpp/pull/1889
* openvino : fix convert-whisper-to-openvino.py for v2023.0.0 (#1870) by @st-gr in https://github.com/ggerganov/whisper.cpp/pull/1890
* ggml : 32-bit arm compat by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1891
* Add SYCL logic in whisper by @abhilash1910 in https://github.com/ggerganov/whisper.cpp/pull/1863
* talk and talk-llama: Pass text_to_speak as a file by @tamo in https://github.com/ggerganov/whisper.cpp/pull/1865
* Stream.wasm: Fix invalid memory access when no segments are returned by @Andrews54757 in https://github.com/ggerganov/whisper.cpp/pull/1902
* Update README to Recommend MacOS Sonoma for Core ML to avoid hallucination by @gavin1818 in https://github.com/ggerganov/whisper.cpp/pull/1917
* Add library versioning by @kenneth-ge in https://github.com/ggerganov/whisper.cpp/pull/1352
* Fix SF(segment fault) issue in Android JNI by @zhouwg in https://github.com/ggerganov/whisper.cpp/pull/1929
* Fix typo in source file whisper.cpp by @zhouwg in https://github.com/ggerganov/whisper.cpp/pull/1925
* bench:fix typo by @zhouwg in https://github.com/ggerganov/whisper.cpp/pull/1933
* Auto lowercase language parameter by @F1L1Pv2 in https://github.com/ggerganov/whisper.cpp/pull/1928
* ggml : try fix 32-bit arm compat by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1938
* whisper : make beam candidate sort more stable by @josharian in https://github.com/ggerganov/whisper.cpp/pull/1943
* bindings/go : add linker flags to make metal work by @josharian in https://github.com/ggerganov/whisper.cpp/pull/1944
* whisper : improve beam search candidate diversity by @josharian in https://github.com/ggerganov/whisper.cpp/pull/1947
* whisper : document whisper_batch.n_seq_id by @josharian in https://github.com/ggerganov/whisper.cpp/pull/1942
* Rename --audio-context to --audio-ctx, as per help text by @joliss in https://github.com/ggerganov/whisper.cpp/pull/1953
* [DRAFT] Token level timestamps with DTW (#375) by @denersc in https://github.com/ggerganov/whisper.cpp/pull/1485
* Fedora dependencies needed (SDL2) by @Man2Dev in https://github.com/ggerganov/whisper.cpp/pull/1970
* libcuda.so.1 in PATH in Docker Container by @tiagofassoni in https://github.com/ggerganov/whisper.cpp/pull/1966
* ruby : fix build by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1980
* Improve support for distil-large-v3 by @sanchit-gandhi in https://github.com/ggerganov/whisper.cpp/pull/1982
* whisper : improve handling of prompts by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1981
* sync : ggml by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/2001
* Implemented command-style grammar in the main example. by @ulatekh in https://github.com/ggerganov/whisper.cpp/pull/1998
* Use pkg-config for OpenBLAS by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1778
* ci : add building in MSYS2 environments (Windows) by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1994
* Support CUDA versions < 11.1 by @primenko-v in https://github.com/ggerganov/whisper.cpp/pull/2020
* Create solution folders in the CMake build by @ulatekh in https://github.com/ggerganov/whisper.cpp/pull/2004
* Allow a regular expression to describe tokens to suppress by @ulatekh in https://github.com/ggerganov/whisper.cpp/pull/1997
* "main" example now allows a response-file as the sole parameter by @ulatekh in https://github.com/ggerganov/whisper.cpp/pull/2019
* Support for CPU BLAS build via Intel MKL by @slashlib in https://github.com/ggerganov/whisper.cpp/pull/2024
* Set stdin to binary mode on Windows. Fixes #2023 by @rotemdan in https://github.com/ggerganov/whisper.cpp/pull/2025
* Fix file-handle leak in read_wav() by @ulatekh in https://github.com/ggerganov/whisper.cpp/pull/2026
* Fix DTW memory access by @bradmurray-dt in https://github.com/ggerganov/whisper.cpp/pull/2012
* whisper: update grammar-parser.cpp by @eltociear in https://github.com/ggerganov/whisper.cpp/pull/2058
* fix missing reference to "model" variable in actual shell command run in whisper.nvim by @sixcircuit in https://github.com/ggerganov/whisper.cpp/pull/2049
* build : detect AVX512 in Makefile, add AVX512 option in CMake by @didzis in https://github.com/ggerganov/whisper.cpp/pull/2043
* feature/no timestamps node by @pprobst in https://github.com/ggerganov/whisper.cpp/pull/2048
* Update embedded Metal library generation process to include dependency by @didzis in https://github.com/ggerganov/whisper.cpp/pull/2045
* server.cpp: add dtw by @eschmidbauer in https://github.com/ggerganov/whisper.cpp/pull/2044
## New Contributors
* @eschmidbauer made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1741
* @RhinoDevel made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1749
* @nank1ro made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1750
* @ghindle made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1755
* @blib made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1753
* @sonphantrung made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1725
* @contractorwolf made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1744
* @Rakksor made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1765
* @rmmh made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1781
* @luciferous made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1785
* @trixirt made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1792
* @mrienstra made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1806
* @JacobLinCool made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1802
* @valenting made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1850
* @dscripka made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1857
* @jumpers775 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1874
* @Theldus made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1872
* @lbluep made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1878
* @st-gr made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1890
* @abhilash1910 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1863
* @Andrews54757 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1902
* @gavin1818 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1917
* @kenneth-ge made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1352
* @zhouwg made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1929
* @F1L1Pv2 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1928
* @josharian made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1943
* @joliss made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1953
* @Man2Dev made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1970
* @tiagofassoni made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1966
* @sanchit-gandhi made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1982
* @ulatekh made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1998
* @primenko-v made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/2020
* @slashlib made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/2024
* @rotemdan made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/2025
* @bradmurray-dt made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/2012
* @sixcircuit made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/2049
* @pprobst made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/2048
**Full Changelog**: https://github.com/ggerganov/whisper.cpp/compare/v1.5.4...v1.5.5
## Overview
- Faster Core ML ANE models (#1716)
- CUDA bugfix causing random erros in the transcription
- Fix SwiftUI example build
**Full Changelog**: https://github.com/ggerganov/whisper.cpp/compare/v1.5.3...v1.5.4
## Overview
Minor maintenance release:
- Fix CUDA issues where the transcription produces garbage
- FIX quantized models to work with CUDA backend
- Allow to use `whisper.cpp` and `llama.cpp` together in SwiftUI projects
## What's Changed
* Update bench.py by @ForkedInTime in https://github.com/ggerganov/whisper.cpp/pull/1655
* cmake : Resolve quantized model issue when CUBLAS enabled by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1667
* examples : Revert CMakeLists.txt for talk-llama by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1669
* CI : Add coverage for talk-llama when WHISPER_CUBLAS=1 by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1672
* ci: build and push docker image by @OpenWaygate in https://github.com/ggerganov/whisper.cpp/pull/1674
* sync : ggml (ggml_scale, ggml_row_size, etc.) by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1677
* Replace `WHISPER_PRINT_DEBUG` with `WHISPER_LOG_DEBUG` by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1681
* download: Fix large q5 model name by @dimopep in https://github.com/ggerganov/whisper.cpp/pull/1695
* sync : ggml (VMM, sync-ggml-am.sh, dotprod ARM fixes) by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1691
* whisper : replace `tensor->n_dims` with `ggml_n_dims(tensor)` by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1694
* Build with CLBlast by @tamo in https://github.com/ggerganov/whisper.cpp/pull/1576
* docker : Fix the Publishing of the CUDA Docker Image by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1704
* emscripten: fix "Stack Overflow!" by @Huguet57 in https://github.com/ggerganov/whisper.cpp/pull/1713
* sync : ggml by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1717
* Add error handling to graph_compute by @finnvoor in https://github.com/ggerganov/whisper.cpp/pull/1714
* Updates Package.swift to use ggml as package dependency by @1-ashraful-islam in https://github.com/ggerganov/whisper.cpp/pull/1701
## New Contributors
* @ForkedInTime made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1655
* @OpenWaygate made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1674
* @dimopep made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1695
* @Huguet57 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1713
* @1-ashraful-islam made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1701
**Full Changelog**: https://github.com/ggerganov/whisper.cpp/compare/v1.5.2...v1.5.3
## Overview
Minor maintenance release:
- Re-enable CPU BLAS processing after fixing a regression (#1583)
Add new example: [wchess](https://github.com/ggerganov/whisper.cpp/tree/master/examples/wchess)
https://github.com/ggerganov/whisper.cpp/assets/1991296/c2b2f03c-9684-49f3-8106-357d2d4e67fa
Shoutout to @fraxy-v (implementation) and @ejones (grammar) for making it work!
## What's Changed
* automatically convert audio on the server by @sapoepsilon in https://github.com/ggerganov/whisper.cpp/pull/1539
* CI : Rectify the Clang-Related workflow issues by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1551
* CI : Add CUDA 11.8.0 support by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1554
* Update main program help info by @bebound in https://github.com/ggerganov/whisper.cpp/pull/1560
* Set default CORS headers to allow all by @kasumi-1 in https://github.com/ggerganov/whisper.cpp/pull/1567
* cmake : install required ggml.h header by @gjasny in https://github.com/ggerganov/whisper.cpp/pull/1568
* Backport .srt output format to examples/server by @osdrv in https://github.com/ggerganov/whisper.cpp/pull/1565
* Added support for .vtt format to Whisper server by @aleksanderandrzejewski in https://github.com/ggerganov/whisper.cpp/pull/1578
* ggml : re-enable blas for src0 != F32 by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1583
* Fix 32-bit compiler warning by @Digipom in https://github.com/ggerganov/whisper.cpp/pull/1575
* Remove #if arch(arm) check in Swift Package Manager by @Finnvoor in https://github.com/ggerganov/whisper.cpp/pull/1561
* Pass max-len argument to server wparams by @osdrv in https://github.com/ggerganov/whisper.cpp/pull/1574
* sync : ggml (new ops, new backend, etc) by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1602
* Fix `ggml_metal_log` on Intel macs by @Finnvoor in https://github.com/ggerganov/whisper.cpp/pull/1606
* Update CMakeLists.txt by @Kreijstal in https://github.com/ggerganov/whisper.cpp/pull/1615
* target windows 8 or above for prefetchVirtualMemory in llama-talk by @Kreijstal in https://github.com/ggerganov/whisper.cpp/pull/1617
* sync : ggml (Metal fixes, new ops, tests) by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1633
* wchess: whisper assisted chess by @fraxy-v in https://github.com/ggerganov/whisper.cpp/pull/1595
## New Contributors
* @sapoepsilon made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1539
* @bebound made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1560
* @kasumi-1 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1567
* @gjasny made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1568
* @osdrv made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1565
* @aleksanderandrzejewski made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1578
* @Kreijstal made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1615
* @fraxy-v made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1595
**Full Changelog**: https://github.com/ggerganov/whisper.cpp/compare/v1.5.1...v1.5.2
## Overview
Minor update:
- With Metal, auto-fallback to CPU if device does not support Apple7 family
- Add [server](https://github.com/ggerganov/whisper.cpp/tree/master/examples/server) example
## What's Changed
* ISSUE-1329: replace " with ' so it doesn't try to execute code in backticks by @spullara in https://github.com/ggerganov/whisper.cpp/pull/1364
* sync : ggml (ggml-alloc + linker + gguf fixes) by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1501
* Fixed with_state methods, to use the correct state by @sandrohanea in https://github.com/ggerganov/whisper.cpp/pull/1519
* #1517 Redistribute CUDA DLLs by @tamo in https://github.com/ggerganov/whisper.cpp/pull/1522
* whisper : reuse whisper_decode_with_state by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1521
* sdl : fix audio callback by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1523
* update deprecated example by @MightyStud in https://github.com/ggerganov/whisper.cpp/pull/1529
* Super Simple Whisper Server by @felrock in https://github.com/ggerganov/whisper.cpp/pull/1380
* Close file after writing in server application by @felrock in https://github.com/ggerganov/whisper.cpp/pull/1533
* bench : multi-thread memcpy by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1534
* Change temp file name for server application by @felrock in https://github.com/ggerganov/whisper.cpp/pull/1535
* Fixed Makefile for MacOS ARM 64 Go bindings by @gleicon in https://github.com/ggerganov/whisper.cpp/pull/1530
* Fixed metal build on macos-latest by @sandrohanea in https://github.com/ggerganov/whisper.cpp/pull/1544
* fix(server): typo in temperature parameter by @Okabintaro in https://github.com/ggerganov/whisper.cpp/pull/1545
* Request to add a new function to get the full language name by @bradmit in https://github.com/ggerganov/whisper.cpp/pull/1546
* server : add --print-realtime param by @ecneladis in https://github.com/ggerganov/whisper.cpp/pull/1541
* cuda : sync some minor stuff from llama.cpp by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1548
* metal : add backend function to check device family support by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1547
## New Contributors
* @spullara made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1364
* @MightyStud made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1529
* @felrock made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1380
* @gleicon made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1530
* @Okabintaro made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1545
* @bradmit made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1546
* @ecneladis made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1541
**Full Changelog**: https://github.com/ggerganov/whisper.cpp/compare/v1.5.0...v1.5.1
## Overview
This major release includes the following changes:
- Full GPU processing of the Encoder and the Decoder with CUDA and Metal is now supported
- Efficient beam-search implementation via batched decoding and unified KV cache
- Full quantization support of all available `ggml` quantization types
- Support for grammar constrained sampling
- Support for Distil Whisper models
- Support for Whisper Large-v3
and more
### Full GPU support
On Apple Silicon, GPU support has been available to a large extend since [15 Sep](https://github.com/ggerganov/whisper.cpp/pull/1270). However, part of the Encoder was still being executed on the CPU due to lack of MSL kernels for the convolution operations. These kernels are now available resulting in additional speed-up of the Encoder in this release:
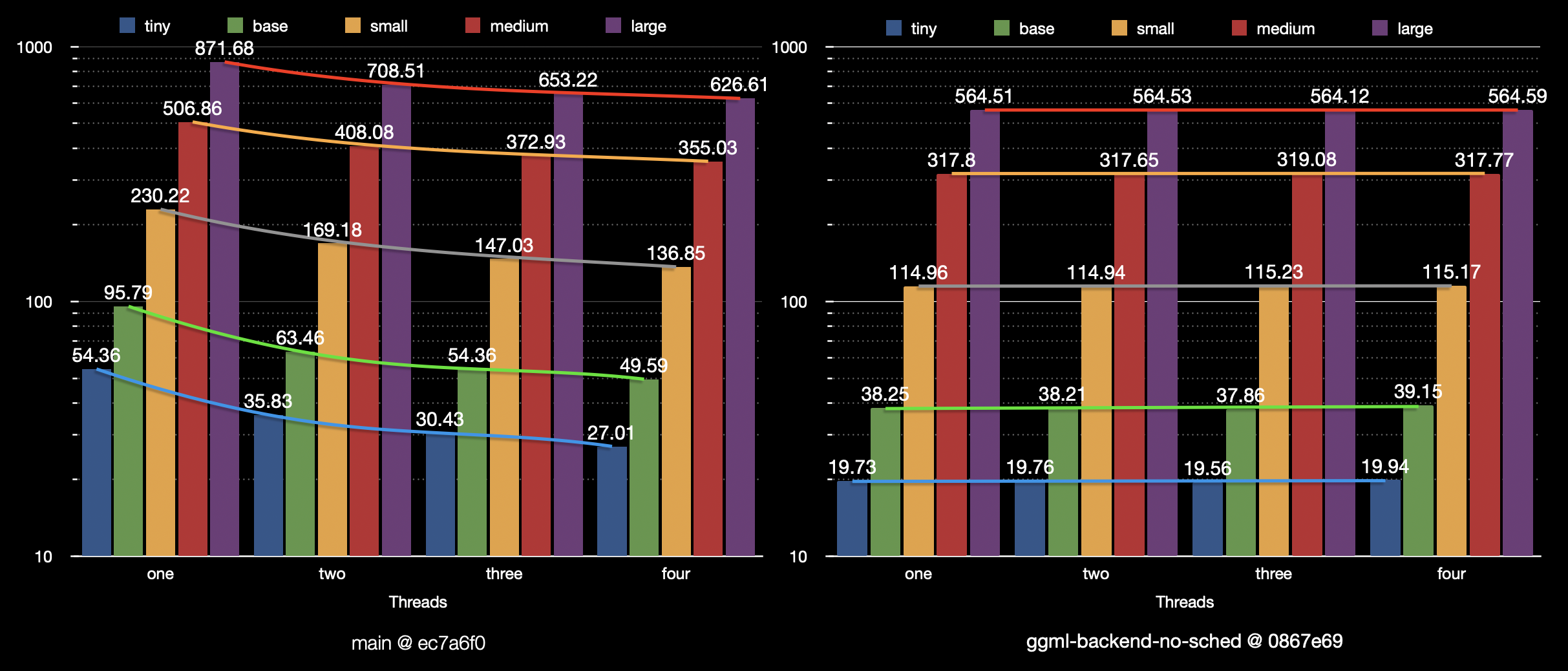
*[Encoder performance on Apple M1 Max - before and after](https://github.com/ggerganov/whisper.cpp/pull/1472#issuecomment-1806788526) (plot by @dreness)*
For NVIDIA hardware, the entire computation can now be offloaded to the GPU which results in significant performance boost. For detailed performance breakdown, checkout the Benchmarks section below.
The GPU processing on Apple Silicon is enabled by default, while for NVIDIA you need to build with `WHISPER_CUBLAS=1`:
```bash
# Apple Silicon
make
# NVIDIA
WHISPER_CUBLAS=1 make
```
Implementation: https://github.com/ggerganov/whisper.cpp/pull/1472
Special credits to: @FSSRepo, @slaren
### Batched decoding + efficient Beam Search
At last, `whisper.cpp` now supports efficient Beam Search decoding. The missing piece was the implementation of batched decoding, which now follows closely the [unified KV cache idea from llama.cpp](https://github.com/ggerganov/llama.cpp/pull/3228). On modern NVIDIA hardware, the performance with 5 beams is the same as 1 beam thanks to the large amount of computing power available. With Metal, the speed with 5 beams is a bit slower compared to 1 beam, but it is significantly faster compared to 5x times the time for single batch which was observed with the old naive implementation.
Beam Search is now enabled by default in `whisper.cpp` to match the OG implementation of OpenAI Whisper. For more performance details, checkout the Benchmarks section below.
Implementation: https://github.com/ggerganov/whisper.cpp/pull/1486
### Quantization support
All `ggml` [quantization types](https://github.com/ggerganov/whisper.cpp/blob/ccc85b4ff8d250d0f25ebcac2be0e4a23401c885/ggml.h#L309-L331) are now supported. Quantization mixtures for Whisper model can be implemented. It's still unclear how the quality is affected from the quantization - this is an interesting area which can be explored in the future.
### Grammar sampling
The decoder output can now be constrained with a [GBNF grammar](https://github.com/ggerganov/llama.cpp/blob/a6fc554e268634494f33b0de76f9dde650dd292f/grammars/README.md). This can be a useful technique for further improving the transcription quality in situations where the set of possible phrases are limited.
https://github.com/ggerganov/whisper.cpp/assets/377495/d24716e2-5e9c-441b-8c6b-395922dccbf4
Implementation: https://github.com/ggerganov/whisper.cpp/pull/1229
Special credits to @ejones
### Distil Whisper
Recently, Distil Whisper models have been released: https://huggingface.co/distil-whisper
`whisper.cpp` offers support for these models, although it still lacks full implementation of the proposed chunking strategy. Performance details for distilled models are included in the Benchmarks section below.
Implementation: https://github.com/ggerganov/whisper.cpp/pull/1424
### Whisper Large-v3
Recently, OpenAI released a new version 3 of the Large model: https://github.com/openai/whisper/pull/1761
Implementation: https://github.com/ggerganov/whisper.cpp/pull/1444
### Benchmarks
Below is a breakdown of the performance of `whisper.cpp` on Apple Silicon, NVIDIA and CPU. The tables show the Encoder and Decoder speed in `ms/tok`. The `Dec.` column corresponds to batch size 1. The `Bch5` column corresponds to batch size 5. The `PP` column corresponds to batch size 128.
For optimal Beam Search performance, the `Bch5` number should be 5 times smaller than `Dec.`
| Hw | Config | Model | Th | Enc. | Dec. | Bch5 | PP | Commit |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| M2 Ultra | METAL | tiny | 1 | 11.14 | 1.40 | 0.49 | 0.01 | ccc85b4 |
| M2 Ultra | METAL | tiny-q5_0 | 1 | 11.51 | 1.41 | 0.52 | 0.01 | ccc85b4 |
| M2 Ultra | METAL | tiny-q5_1 | 1 | 12.21 | 1.41 | 0.52 | 0.01 | ccc85b4 |
| M2 Ultra | METAL | base | 1 | 20.21 | 2.05 | 0.77 | 0.02 | ccc85b4 |
| M2 Ultra | METAL | base-q5_0 | 1 | 19.89 | 1.96 | 0.81 | 0.02 | ccc85b4 |
| M2 Ultra | METAL | base-q5_1 | 1 | 20.14 | 2.02 | 0.81 | 0.02 | ccc85b4 |
| M2 Ultra | METAL | small | 1 | 51.01 | 3.97 | 1.74 | 0.05 | ccc85b4 |
| M2 Ultra | METAL | small-q5_0 | 1 | 56.86 | 4.09 | 1.85 | 0.06 | ccc85b4 |
| M2 Ultra | METAL | small-q5_1 | 1 | 56.81 | 4.14 | 1.85 | 0.06 | ccc85b4 |
| M2 Ultra | METAL | medium | 1 | 141.21 | 8.47 | 3.98 | 0.13 | ccc85b4 |
| M2 Ultra | METAL | medium-q5_0 | 1 | 160.56 | 8.27 | 4.18 | 0.14 | ccc85b4 |
| M2 Ultra | METAL | medium-q5_1 | 1 | 160.52 | 8.40 | 4.15 | 0.14 | ccc85b4 |
| M2 Ultra | METAL | medium-dis | 1 | 128.14 | 1.13 | 0.43 | 0.02 | ccc85b4 |
| M2 Ultra | METAL | large-v2 | 1 | 248.73 | 11.96 | 6.08 | 0.22 | ccc85b4 |
| M2 Ultra | METAL | large-v2-q5_0 | 1 | 286.31 | 11.99 | 6.60 | 0.26 | ccc85b4 |
| M2 Ultra | METAL | large-v2-q5_1 | 1 | 284.56 | 12.42 | 6.47 | 0.26 | ccc85b4 |
| M2 Ultra | METAL | large-v2-dis | 1 | 224.31 | 1.26 | 0.49 | 0.02 | ccc85b4 |
| Hw | Config | Model | Th | Enc. | Dec. | Bch5 | PP | Commit |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| M2 Ultra | COREML METAL | tiny | 1 | 7.60 | 1.41 | 0.50 | 0.01 | ccc85b4 |
| M2 Ultra | COREML METAL | base | 1 | 11.90 | 2.07 | 0.78 | 0.02 | ccc85b4 |
| M2 Ultra | COREML METAL | small | 1 | 32.19 | 4.10 | 1.78 | 0.05 | ccc85b4 |
| M2 Ultra | COREML METAL | medium | 1 | 94.43 | 8.40 | 3.89 | 0.12 | ccc85b4 |
| M2 Ultra | COREML METAL | large-v2 | 1 | 179.78 | 12.12 | 6.07 | 0.22 | ccc85b4 |
| Hw | Config | Model | Th | Enc. | Dec. | Bch5 | PP | Commit |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| NVIDIA V100 | BLAS CUDA | tiny | 1 | 8.84 | 1.62 | 0.33 | 0.02 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | tiny-q5_0 | 1 | 8.43 | 1.19 | 0.31 | 0.02 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | tiny-q5_1 | 1 | 8.41 | 1.19 | 0.29 | 0.02 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | base | 1 | 14.79 | 2.31 | 0.46 | 0.03 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | base-q5_0 | 1 | 15.05 | 1.66 | 0.44 | 0.03 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | base-q5_1 | 1 | 15.01 | 1.68 | 0.46 | 0.03 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | small | 1 | 40.30 | 4.37 | 0.88 | 0.05 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | small-q5_0 | 1 | 41.17 | 3.11 | 0.94 | 0.05 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | small-q5_1 | 1 | 41.12 | 3.11 | 0.82 | 0.05 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | medium | 1 | 104.93 | 10.06 | 1.77 | 0.11 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | medium-q5_0 | 1 | 107.11 | 6.13 | 2.07 | 0.12 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | medium-q5_1 | 1 | 107.91 | 6.21 | 1.77 | 0.12 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | medium-dis | 1 | 103.45 | 1.11 | 0.24 | 0.02 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | large-v2 | 1 | 171.55 | 15.76 | 2.62 | 0.17 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | large-v2-q5_0 | 1 | 176.27 | 8.61 | 3.17 | 0.19 | ccc85b4 |
| NVIDIA V100 | BLAS CUDA | large-v2-q5_1 | 1 | 176.23 | 8.67 | 2.59 | 0.19 | ccc85b4 |
| Hw | Config | Model | Th | Enc. | Dec. | Bch5 | PP | Commit |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| AMD Ryzen 9 5950X | AVX2 | tiny | 8 | 197.47 | 1.22 | 0.44 | 0.25 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | tiny-q5_0 | 8 | 222.92 | 0.87 | 0.45 | 0.30 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | tiny-q5_1 | 8 | 221.25 | 0.89 | 0.45 | 0.30 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | base | 8 | 427.14 | 3.11 | 0.88 | 0.43 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | base-q5_0 | 8 | 474.96 | 1.41 | 0.72 | 0.51 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | base-q5_1 | 8 | 485.05 | 1.48 | 0.73 | 0.52 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | small | 8 | 1470.51 | 11.70 | 2.89 | 1.21 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | small-q5_0 | 8 | 1700.43 | 5.48 | 1.98 | 1.41 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | small-q5_1 | 8 | 1719.03 | 5.79 | 2.02 | 1.42 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | medium | 8 | 4417.70 | 35.13 | 8.14 | 3.24 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | medium-q5_0 | 8 | 5335.77 | 17.44 | 5.35 | 3.92 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | medium-q5_1 | 8 | 5372.26 | 18.36 | 5.42 | 3.88 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | medium-dis | 8 | 4070.25 | 4.86 | 1.16 | 0.53 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | large-v2 | 8 | 8179.09 | 66.89 | 15.45 | 5.88 | ccc85b4 |
| AMD Ryzen 9 5950X | AVX2 | large-v2-dis | 8 | 7490.45 | 7.06 | 1.63 | 0.70 | ccc85b4 |
### API Changes
- Add `struct whisper_context_params`
- Add `whisper_log_set`
- Deprecate:
- `whisper_init_from_file`
- `whisper_init_from_buffer`
- `whisper_init`
- `whisper_init_from_file_no_state`
- `whisper_init_from_buffer_no_state`
- `whisper_init_no_state`
- Add:
- `whisper_init_from_file_with_params`
- `whisper_init_from_buffer_with_params`
- `whisper_init_with_params`
- `whisper_init_from_file_with_params_no_state`
- `whisper_init_from_buffer_with_params_no_state`
- `whisper_init_with_params_no_state`
- Diff of `struct whisper_full_params`
```diff
struct whisper_full_params {
enum whisper_sampling_strategy strategy;
@@ -338,6 +435,7 @@ extern "C" {
bool translate;
bool no_context; // do not use past transcription (if any) as initial prompt for the decoder
+ bool no_timestamps; // do not generate timestamps
bool single_segment; // force single segment output (useful for streaming)
bool print_special; // print special tokens (e.g. <SOT>, <EOT>, <BEG>, etc.)
bool print_progress; // print progress information
@@ -355,8 +453,12 @@ extern "C" {
// [EXPERIMENTAL] speed-up techniques
// note: these can significantly reduce the quality of the output
bool speed_up; // speed-up the audio by 2x using Phase Vocoder
+ bool debug_mode; // enable debug_mode provides extra info (eg. Dump log_mel)
int audio_ctx; // overwrite the audio context size (0 = use default)
+ // [EXPERIMENTAL] [TDRZ] tinydiarize
+ bool tdrz_enable; // enable tinydiarize speaker turn detection
+
// tokens to provide to the whisper decoder as initial prompt
// these are prepended to any existing text context from a previous call
const char * initial_prompt;
@@ -365,6 +467,7 @@ extern "C" {
// for auto-detection, set to nullptr, "" or "auto"
const char * language;
+ bool detect_language;
// common decoding parameters:
bool suppress_blank; // ref: https://github.com/openai/whisper/blob/f82bc59f5ea234d4b97fb2860842ed38519f7e65/whisper/decoding.py#L89
@@ -403,11 +506,24 @@ extern "C" {
whisper_encoder_begin_callback encoder_begin_callback;
void * encoder_begin_callback_user_data;
+ // called each time before ggml computation starts
+ whisper_abort_callback abort_callback;
+ void * abort_callback_user_data;
+
// called by each decoder to filter obtained logits
whisper_logits_filter_callback logits_filter_callback;
void * logits_filter_callback_user_data;
+
+ const whisper_grammar_element ** grammar_rules;
+ size_t n_grammar_rules;
+ size_t i_start_rule;
+ float grammar_penalty;
};
```
There might be some instability around the API, especially with the existing language bindings. I wasn't able to test everything, so expect some issues and feel free to submit PRs with any kind of fixes that you find.
## Highlights and what's next
A lot of the updates in these release are possible thanks to the many contributions in [llama.cpp](https://github.com/ggerganov/llama.cpp) - huge shoutout to all the contributors and collaborators there!
Regarding future updates to `whisper.cpp`, I'm looking forward to the following things:
- Add server example similar to the one in `llama.cpp`
- Try to improve Metal's batched decoding performance
- Look for some interesting applications of the grammar sampling functionality
---
- **Latest performance of the [talk-llama](https://github.com/ggerganov/whisper.cpp/tree/master/examples/talk-llama) example**
https://github.com/ggerganov/whisper.cpp/assets/1991296/d97a3788-bf2a-4756-9a43-60c6b391649e
## What's Changed
* Fix quantize bug by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/842
* whisper.wasm : fix typo in readme by @BaffinLee in https://github.com/ggerganov/whisper.cpp/pull/832
* Adding --session support in examples/talk-llama by @herrera-luis in https://github.com/ggerganov/whisper.cpp/pull/845
* --detect-language mode by @CRD716 in https://github.com/ggerganov/whisper.cpp/pull/853
* talk-llama: updating session prompts load by @herrera-luis in https://github.com/ggerganov/whisper.cpp/pull/854
* CMake/Makefile : CLBlast support as in llama.cpp by @trholding in https://github.com/ggerganov/whisper.cpp/pull/862
* Instruction: Partial OpenCL GPU support via CLBlast by @trholding in https://github.com/ggerganov/whisper.cpp/pull/863
* Add cuBLAS build workflow and fix error causing lines in CMakeLists by @RelatedTitle in https://github.com/ggerganov/whisper.cpp/pull/867
* cmake : fix options disabling AVX and AVX2 flags by @blazingzephyr in https://github.com/ggerganov/whisper.cpp/pull/885
* Added large-v2. Added instructions on converting to GGML. Added --no-… by @cjheath in https://github.com/ggerganov/whisper.cpp/pull/874
* talk-llama: only copy used KV cache in get / set state by @herrera-luis in https://github.com/ggerganov/whisper.cpp/pull/890
* Fix define used for COREML_ALLOW_FALLBACK by @jcsoo in https://github.com/ggerganov/whisper.cpp/pull/893
* coreml : fix memory leak by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/899
* whisper.objc : enable Core ML in example & fix segmentation fault by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/910
* Align --no-timestamps in help to actual behavior by @Miserlou in https://github.com/ggerganov/whisper.cpp/pull/908
* readme : improve Core ML model conversion guidance by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/915
* Added support of large-v1 model into CoreML by @abCods in https://github.com/ggerganov/whisper.cpp/pull/926
* Update of Hebrew Language Code: 'iw' to 'he' by @ttv20 in https://github.com/ggerganov/whisper.cpp/pull/935
* java bindings by @nalbion in https://github.com/ggerganov/whisper.cpp/pull/931
* ci: Build with any BLAS compatible library by @akharlamov in https://github.com/ggerganov/whisper.cpp/pull/927
* [DOCS] highlight openblas support in https://github.com/ggerganov/whisper.cpp/pull/956
* Update elevenlabs example to use official python API by @DGdev91 in https://github.com/ggerganov/whisper.cpp/pull/837
* Update README.md by @genevera in https://github.com/ggerganov/whisper.cpp/pull/964
* Feature/java bindings2 by @nalbion in https://github.com/ggerganov/whisper.cpp/pull/944
* Support decode wav file has 2 channels. by @geniusnut in https://github.com/ggerganov/whisper.cpp/pull/972
* README.md: Corrected syntax for markdown link by @LarryBattle in https://github.com/ggerganov/whisper.cpp/pull/995
* Make convert-pt-to-ggml.py backwards compatible with older vocab.json tokenizer files by @akashmjn in https://github.com/ggerganov/whisper.cpp/pull/1001
* Fixing Accidental 'exit(0)' and Ensuring Proper 'return 1' in `examples/main/main.cpp` `whisper_params_parse` by @faker2048 in https://github.com/ggerganov/whisper.cpp/pull/1002
* Fix for issue #876 by @burningion in https://github.com/ggerganov/whisper.cpp/pull/1012
* Make cuBLAS compilation compatible with x86 as well as aarch64 by @byte-6174 in https://github.com/ggerganov/whisper.cpp/pull/1015
* feat(golang): improve progress reporting and callback handling by @appleboy in https://github.com/ggerganov/whisper.cpp/pull/1024
* Add support for whisper_full_lang_id() to go bindings by @jaybinks in https://github.com/ggerganov/whisper.cpp/pull/1010
* Add alternative java binding to readme by @GiviMAD in https://github.com/ggerganov/whisper.cpp/pull/1029
* diarization: add diarization support for all current output types by @colinc in https://github.com/ggerganov/whisper.cpp/pull/1031
* Fix cd statements to allow spaces in model path by @roddurd in https://github.com/ggerganov/whisper.cpp/pull/1041
* adding ggml_to_pt script by @simonMoisselin in https://github.com/ggerganov/whisper.cpp/pull/1042
* whisper: Fix build with -Werror=undef by @philn in https://github.com/ggerganov/whisper.cpp/pull/1045
* Fix talk-llama build after ggml sync (commit 5feb0dffbae5). by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1049
* Do not use _GNU_SOURCE gratuitously. by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1027
* whisper : `split_on_word` no longer trims by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1046
* Updated 'quantize-all.sh' to quantize all downloaded models by @thefinaldegree in https://github.com/ggerganov/whisper.cpp/pull/1054
* Fix talk-llama build on macOS. by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1062
* whisper : support speaker segmentation (local diarization) of mono audio via tinydiarize by @akashmjn in https://github.com/ggerganov/whisper.cpp/pull/1058
* Minor: updated readme by @mwarnaar in https://github.com/ggerganov/whisper.cpp/pull/1064
* OpenVINO support by @RyanMetcalfeInt8 in https://github.com/ggerganov/whisper.cpp/pull/1037
* go bindings: fix context.Process call in examples by @mvrilo in https://github.com/ggerganov/whisper.cpp/pull/1067
* go: Call SetDuration appropriately by @tmc in https://github.com/ggerganov/whisper.cpp/pull/1077
* Multi platforms CI by @alonfaraj in https://github.com/ggerganov/whisper.cpp/pull/1101
* Add Vim plugin by @AustinMroz in https://github.com/ggerganov/whisper.cpp/pull/1131
* chore: move progress calculation out of whisper.cpp by @geekodour in https://github.com/ggerganov/whisper.cpp/pull/1081
* expose api to let user control log output by @evmar in https://github.com/ggerganov/whisper.cpp/pull/1060
* Add a larger (30min) sample by @vadi2 in https://github.com/ggerganov/whisper.cpp/pull/1092
* Sync opencl compilation fix in ggml by @goncha in https://github.com/ggerganov/whisper.cpp/pull/1111
* README.md: Add OpenVINO support details by @RyanMetcalfeInt8 in https://github.com/ggerganov/whisper.cpp/pull/1112
* Fix MSVC compile error C3688 on non-unicode Windows by @goncha in https://github.com/ggerganov/whisper.cpp/pull/1110
* Now make tests can be called as make tests base.en by @Jerry-Master in https://github.com/ggerganov/whisper.cpp/pull/1113
* Go binding: Implement SetSplitOnWord by @xdrudis in https://github.com/ggerganov/whisper.cpp/pull/1114
* set NVCC -arch flag by cuda version by @alonfaraj in https://github.com/ggerganov/whisper.cpp/pull/1115
* Fix CLBlast build on MacOS by @iceychris in https://github.com/ggerganov/whisper.cpp/pull/1120
* Fixed the issue of OpenBLAS not being enabled on Windows. by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1128
* whisper : fix visibility warning of struct whisper_full_params by declaring in advance by @IronBlood in https://github.com/ggerganov/whisper.cpp/pull/1124
* Fix MSVC compile error C3688 by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1136
* Add tinydiarization support for streaming by @DMcConnell in https://github.com/ggerganov/whisper.cpp/pull/1137
* quantize : fix load vocab crash when len is 128 by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/1160
* Fix AVX etc. under GCC/CMake by @marmistrz in https://github.com/ggerganov/whisper.cpp/pull/1174
* Fix PowerPC build failures introduced in #1174 by @marmistrz in https://github.com/ggerganov/whisper.cpp/pull/1196
* Simplify Makefile by @alonfaraj in https://github.com/ggerganov/whisper.cpp/pull/1147
* Add precalculated values of sin/cos for speeding up FFT by @AlexandrGraschenkov in https://github.com/ggerganov/whisper.cpp/pull/1142
* Make build work on Linux machines supporting AVX1 not AVX2 by @lachesis in https://github.com/ggerganov/whisper.cpp/pull/1162
* Fix OpenBLAS detection under Arch Linux by @marmistrz in https://github.com/ggerganov/whisper.cpp/pull/1173
* Minor fixes by @csukuangfj in https://github.com/ggerganov/whisper.cpp/pull/1154
* New command line option by @jbyunes in https://github.com/ggerganov/whisper.cpp/pull/1205
* whisper.android : migrate from ndk-build to CMake by @JunkFood02 in https://github.com/ggerganov/whisper.cpp/pull/1204
* Significantly improve whisper.cpp inference quality by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1148
* whisper : allow whisper_full from mel spectrogram - no audio by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1214
* ROCm Port by @ardfork in https://github.com/ggerganov/whisper.cpp/pull/1209
* Improvements to vim plugin and LSP server by @AustinMroz in https://github.com/ggerganov/whisper.cpp/pull/1144
* Detect SSSE3 by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1211
* ggml : fix compiling when SSE3 is available but not SSSE3 by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1210
* make : add support for building on DragonFlyBSD/NetBSD/OpenBSD by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1212
* make : use cpuinfo in MSYS2 to enable x86 ISA extensions on the host by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1216
* Fix CoreML memleak (fixes #1202) by @denersc in https://github.com/ggerganov/whisper.cpp/pull/1218
* whisper.android : fix cmake multiple libraries build by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/1224
* Fix compilation errors incurred by -Werror by @shivamidow in https://github.com/ggerganov/whisper.cpp/pull/1227
* ci : enable java package publishing by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1228
* fix cmake commands in README #1225 by @wizardforcel in https://github.com/ggerganov/whisper.cpp/pull/1231
* ggml : sync (ggml-alloc, GPU, eps, etc.) by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1220
* make : improve cpuinfo handling on x86 hosts by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1238
* ggml : sync latest llama.cpp (view_src + alloc improvements) by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1247
* Posixify pagesize. by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1251
* Fix detection of AVX2 on macOS by @didzis in https://github.com/ggerganov/whisper.cpp/pull/1250
* Address ARM's big.LITTLE arch by checking cpu info. by @Digipom in https://github.com/ggerganov/whisper.cpp/pull/1254
* Bump gradle plugin and dependencies + a lint pass by @Digipom in https://github.com/ggerganov/whisper.cpp/pull/1255
* Add quantized models to download-ggml-model.sh by @nchudleigh in https://github.com/ggerganov/whisper.cpp/pull/1235
* Do not use _GNU_SOURCE gratuitously. by @przemoc in https://github.com/ggerganov/whisper.cpp/pull/1129
* ci : upgrade gradle to 2.4.2 by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1263
* sync : ggml (HBM + Metal + style) by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1264
* ci : try to fix gradle action by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1265
* Fixed signing of java artifact using gradle by @nalbion in https://github.com/ggerganov/whisper.cpp/pull/1267
* Faster `beam_search` sampling by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1243
* whisper : fix bench regression by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1275
* whisper : Metal and ggml-alloc support by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1270
* bench: fix missing include by @nekr0z in https://github.com/ggerganov/whisper.cpp/pull/1303
* ruby : fix build by add missing ggml-alloc by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/1305
* Update README.md. Adding missing options, remove `--speed-up`. by @Sogl in https://github.com/ggerganov/whisper.cpp/pull/1306
* Update README.md by @computerscienceiscool in https://github.com/ggerganov/whisper.cpp/pull/1290
* save the recorded audio to a file by @litongjava in https://github.com/ggerganov/whisper.cpp/pull/1310
* Python benchmark script by @nchudleigh in https://github.com/ggerganov/whisper.cpp/pull/1298
* Minor: fix example talk readme gpt-2 github url by @brunofaustino in https://github.com/ggerganov/whisper.cpp/pull/1334
* Missing speaker turn function in API by @didzis in https://github.com/ggerganov/whisper.cpp/pull/1330
* examples: Move wav_writer from stream.cpp to common.h by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1317
* Better abort callback by @mkiol in https://github.com/ggerganov/whisper.cpp/pull/1335
* Add conversion scripts from HuggingFace models to CoreML by @AlienKevin in https://github.com/ggerganov/whisper.cpp/pull/1304
* Prefer pkg-config while looking for BLAS by @marmistrz in https://github.com/ggerganov/whisper.cpp/pull/1349
* Abort build if a feature was requested and could not be configured by @marmistrz in https://github.com/ggerganov/whisper.cpp/pull/1350
* Abort callback improvements by @mkiol in https://github.com/ggerganov/whisper.cpp/pull/1345
* Dockerfile for cublas by @joecryptotoo in https://github.com/ggerganov/whisper.cpp/pull/1286
* docs: fix typo by @jorismertz in https://github.com/ggerganov/whisper.cpp/pull/1362
* Expose the audio_ctx param through the Go binding by @JohanRaffin in https://github.com/ggerganov/whisper.cpp/pull/1368
* Clarify doc about where to compile from by @ai-at-home in https://github.com/ggerganov/whisper.cpp/pull/1400
* Faster download for models on windows using BitTransfer by @WhiteOlivierus in https://github.com/ggerganov/whisper.cpp/pull/1404
* JSON: allow outputting per-token data too by @akx in https://github.com/ggerganov/whisper.cpp/pull/1358
* Move up-to-date demo to top by @asadm in https://github.com/ggerganov/whisper.cpp/pull/1417
* Use absolute paths for the converted OpenVINO model by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1356
* sync : ggml (backend v2, k-quants, CUDA opts, Metal opts, etc.) by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1422
* whisper : add support for new distilled Whisper models by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1424
* whisper : add context param for disable gpu by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/1293
* talk-llama : fix n_gpu_layers usage by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/1441
* talk-llama : fix n_gpu_layers usage again by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/1442
* Fix variable names in GitHub actions config by @iamthad in https://github.com/ggerganov/whisper.cpp/pull/1440
* Reset ctx->t_start_us when calling whisper_reset_timings() by @bjnortier in https://github.com/ggerganov/whisper.cpp/pull/1434
* Decouple Android example into a library and app module by @tobrun in https://github.com/ggerganov/whisper.cpp/pull/1445
* whisper : add support for large v3 by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1444
* Add support for Swift Package Manager by @sindresorhus in https://github.com/ggerganov/whisper.cpp/pull/1370
* Reset mel time when resetting timings by @bjnortier in https://github.com/ggerganov/whisper.cpp/pull/1452
* coreml: use the correct n_mel by @jxy in https://github.com/ggerganov/whisper.cpp/pull/1458
* models : Fix `n_mel` mismatch in convert-whisper-to-openvino.py by @bobqianic in https://github.com/ggerganov/whisper.cpp/pull/1459
* Add '-l auto' to talk-llama example by @kubaracek in https://github.com/ggerganov/whisper.cpp/pull/1467
* Return with error from whisper_encode_internal and whisper_decode_int… by @bjnortier in https://github.com/ggerganov/whisper.cpp/pull/1456
* whisper : add full CUDA and Metal offloading by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1472
* examples : Enhanced compatibility with older Android versions using Java by @litongjava in https://github.com/ggerganov/whisper.cpp/pull/1382
* Add n_gpu_layers option to talk-llama example by @rlapray in https://github.com/ggerganov/whisper.cpp/pull/1475
* whisper : add grammar-based sampling by @ejones in https://github.com/ggerganov/whisper.cpp/pull/1229
* java : use tiny.en for tests by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1484
* whisper : add batched decoding by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1486
* java : fix test by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1492
* whisper : make large version explicit + fix data size units by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/1493
## New Contributors
* @BaffinLee made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/832
* @herrera-luis made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/845
* @CRD716 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/853
* @trholding made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/862
* @RelatedTitle made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/867
* @blazingzephyr made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/885
* @cjheath made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/874
* @jcsoo made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/893
* @Miserlou made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/908
* @abCods made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/926
* @ttv20 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/935
* @nalbion made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/931
* @akharlamov made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/927
* @geniusnut made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/972
* @LarryBattle made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/995
* @akashmjn made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1001
* @faker2048 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1002
* @burningion made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1012
* @byte-6174 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1015
* @appleboy made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1024
* @jaybinks made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1010
* @GiviMAD made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1029
* @colinc made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1031
* @roddurd made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1041
* @simonMoisselin made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1042
* @philn made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1045
* @przemoc made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1049
* @thefinaldegree made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1054
* @mwarnaar made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1064
* @RyanMetcalfeInt8 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1037
* @mvrilo made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1067
* @tmc made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1077
* @alonfaraj made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1101
* @AustinMroz made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1131
* @geekodour made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1081
* @evmar made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1060
* @vadi2 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1092
* @goncha made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1111
* @Jerry-Master made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1113
* @xdrudis made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1114
* @iceychris made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1120
* @bobqianic made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1128
* @IronBlood made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1124
* @DMcConnell made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1137
* @marmistrz made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1174
* @AlexandrGraschenkov made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1142
* @lachesis made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1162
* @csukuangfj made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1154
* @jbyunes made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1205
* @JunkFood02 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1204
* @ardfork made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1209
* @denersc made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1218
* @shivamidow made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1227
* @wizardforcel made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1231
* @didzis made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1250
* @nchudleigh made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1235
* @nekr0z made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1303
* @Sogl made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1306
* @computerscienceiscool made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1290
* @litongjava made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1310
* @brunofaustino made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1334
* @mkiol made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1335
* @AlienKevin made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1304
* @joecryptotoo made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1286
* @jorismertz made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1362
* @JohanRaffin made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1368
* @ai-at-home made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1400
* @WhiteOlivierus made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1404
* @akx made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1358
* @asadm made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1417
* @iamthad made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1440
* @bjnortier made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1434
* @tobrun made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1445
* @sindresorhus made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1370
* @jxy made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1458
* @kubaracek made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1467
* @rlapray made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/1475
**Full Changelog**: https://github.com/ggerganov/whisper.cpp/compare/v1.4.0...v1.5.0
This is a minor release, the main reason for which is that there hasn't been an official release for a few months now and some small things have accumulated on the `master` branch that would be nice to be upstreamed. I am planning a major `v1.5.0` release with some new and long-waited functionality soon:
- Full CUDA offloading
- Efficient Beam-Search implementation
- Grammar support
The current version `v1.4.3` should be considered in beta as I haven't worked intensively on `whisper.cpp` recently and there might be some issues that made their way in the code. I'll try to polish things in the next days and prepare a stable `v1.5.0` release. In the meantime, any feedback will be highly appreciated.
***Detailed API changes, features and new contributor recognitions will be included in the `v1.5.0` release.***
## Overview
This is a new major release adding **integer quantization** and **partial GPU (NVIDIA)** support
### Integer quantization
This allows the `ggml` Whisper models to be converted from the default 16-bit floating point weights to 4, 5 or 8 bit integer weights.
The resulting quantized models are smaller in disk size and memory usage and can be processed faster on some architectures. The transcription quality is degraded to some extend - not quantified at the moment.
- Supported quantization modes: `Q4_0`, `Q4_1`, `Q4_2`, `Q5_0`, `Q5_1`, `Q8_0`
- Implementation details: https://github.com/ggerganov/whisper.cpp/pull/540
- Usage instructions: [README](https://github.com/ggerganov/whisper.cpp#quantization)
- All WASM examples now support `Q5` quantized models: https://whisper.ggerganov.com
Here is a quantitative evaluation of the different quantization modes applied to the [LLaMA](https://github.com/facebookresearch/llama) and [RWKV](https://github.com/BlinkDL/RWKV-LM) large language models. These results can give an impression about the expected quality, size and speed for quantized Whisper models:
#### LLaMA quantization (measured on M1 Pro)
| Model | Measure | F16 | Q4_0 | Q4_1 | Q4_2 | Q5_0 | Q5_1 | Q8_0 |
|------:|--------------|-------:|-------:|-------:|-------:|-------:|-------:|-------:|
| 7B | perplexity | 5.9565 | 6.2103 | 6.1286 | 6.1698 | 6.0139 | 5.9934 | 5.9571 |
| 7B | file size | 13.0G | 4.0G | 4.8G | 4.0G | 4.4G | 4.8G | 7.1G |
| 7B | ms/tok @ 4th | 128 | 56 | 61 | 84 | 91 | 95 | 75 |
| 7B | ms/tok @ 8th | 128 | 47 | 55 | 48 | 53 | 59 | 75 |
| 7B | bits/weight | 16.0 | 5.0 | 6.0 | 5.0 | 5.5 | 6.0 | 9.0 |
| 13B | perplexity | 5.2455 | 5.3748 | 5.3471 | 5.3433 | 5.2768 | 5.2582 | 5.2458 |
| 13B | file size | 25.0G | 7.6G | 9.1G | 7.6G | 8.4G | 9.1G | 14G |
| 13B | ms/tok @ 4th | 239 | 104 | 113 | 160 | 176 | 185 | 141 |
| 13B | ms/tok @ 8th | 240 | 85 | 99 | 97 | 108 | 117 | 147 |
| 13B | bits/weight | 16.0 | 5.0 | 6.0 | 5.0 | 5.5 | 6.0 | 9.0 |
ref: https://github.com/ggerganov/llama.cpp#quantization
#### RWKV quantization
| Format | Perplexity (169M) | Latency, ms (1.5B) | File size, GB (1.5B) |
|-----------|-------------------|--------------------|----------------------|
| `Q4_0` | 17.507 | *76* | **1.53** |
| `Q4_1` | 17.187 | **72** | 1.68 |
| `Q4_2` | 17.060 | 85 | **1.53** |
| `Q5_0` | 16.194 | 78 | *1.60* |
| `Q5_1` | 15.851 | 81 | 1.68 |
| `Q8_0` | *15.652* | 89 | 2.13 |
| `FP16` | **15.623** | 117 | 2.82 |
| `FP32` | **15.623** | 198 | 5.64 |
ref: https://github.com/ggerganov/ggml/issues/89#issuecomment-1528781992
This feature is possible thanks to the many contributions in the [llama.cpp](https://github.com/ggerganov/llama.cpp) project: https://github.com/users/ggerganov/projects/2
### GPU support via cuBLAS
Using cuBLAS results mainly in improved Encoder inference speed. I haven't done proper timings, but one can expect at least 2-3 times faster Encoder evaluation with modern NVIDIA GPU cards compared to CPU-only processing. Feel free to post your Encoder benchmarks in issue #89.
- Implementation details: https://github.com/ggerganov/whisper.cpp/pull/834
- Usage instructions: [README](https://github.com/ggerganov/whisper.cpp#nvidia-gpu-support-via-cublas)
This is another feature made possible by the [llama.cpp](https://github.com/ggerganov/llama.cpp) project. Special recognition to @slaren for putting almost all of this work together
---
This release remains in "beta" stage as I haven't verified that everything works as expected.
## What's Changed
* Updated escape_double_quotes() Function by @tauseefmohammed2 in https://github.com/ggerganov/whisper.cpp/pull/776
* examples : add missing #include <cstdint> by @pH5 in https://github.com/ggerganov/whisper.cpp/pull/798
* Flush upon finishing inference by @tarasglek in https://github.com/ggerganov/whisper.cpp/pull/811
* Escape quotes in csv output by @laytan in https://github.com/ggerganov/whisper.cpp/pull/815
* C++11style by @wuyudi in https://github.com/ggerganov/whisper.cpp/pull/768
* Optionally allow a Core ML build of Whisper to work with or without Core ML models by @Canis-UK in https://github.com/ggerganov/whisper.cpp/pull/812
* add some tips about in the readme of the android project folder by @Zolliner in https://github.com/ggerganov/whisper.cpp/pull/816
* whisper: Use correct seek_end when offset is used by @ThijsRay in https://github.com/ggerganov/whisper.cpp/pull/833
* ggml : fix 32-bit ARM NEON by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/836
* Add CUDA support via cuBLAS by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/834
* Integer quantisation support by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/540
## New Contributors
* @tauseefmohammed2 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/776
* @pH5 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/798
* @tarasglek made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/811
* @laytan made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/815
* @wuyudi made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/768
* @Canis-UK made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/812
* @Zolliner made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/816
* @ThijsRay made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/833
**Full Changelog**: https://github.com/ggerganov/whisper.cpp/compare/v1.3.0...v1.4.0
## Overview
This release should be considered in Beta stage, since I haven't done a lot of testing and I am not sure if I didn't break something.
But overall, I believe both the performance and the quality are improved.
- Added Core ML support #566
- Restored decoding fallbacks with default size of 2 instead of 5 (f19e23fbd108ec3ac458c7a19b31c930719e7a94)
- Pad the audio with zeros instead of the spectrogram (5108b30e6daf361c856abb6b86e5038500bdbeb1)
- Added [talk-llama](https://github.com/ggerganov/whisper.cpp/tree/master/examples/talk-llama) example
- Added `whisper_state` which allows parallel transcriptions with a single model in memory (#523)
The C-style API has been extended significantly to support the new `whisper_state`, but in general should be backwards compatible.
The only breaking change is in the callbacks signatures.
Please provide feedback in the discussion if you observe any issues.
The next release `v1.4.0` will follow up relatively soon and will provide 4-bit integer quantization support.
## What's Changed
* update csv output format to match OpenAI's Whisper dataframe output by @hykelvinlee42 in https://github.com/ggerganov/whisper.cpp/pull/552
* Go binding: NewContext now returns a clean context by @polarmoon in https://github.com/ggerganov/whisper.cpp/pull/537
* Added whisper state + default state on the whisper_context by @sandrohanea in https://github.com/ggerganov/whisper.cpp/pull/523
* whisper.android: Enable fp16 instrinsics (FP16_VA) which is supported by ARMv8.2 or later. by @tinoue in https://github.com/ggerganov/whisper.cpp/pull/572
* Add quality comparison helper by @venkr in https://github.com/ggerganov/whisper.cpp/pull/569
* whisper.android: Support benchmark for Android example. by @tinoue in https://github.com/ggerganov/whisper.cpp/pull/542
* Fix MUSL Linux build by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/576
* Change default encoding to UTF-8 by @Kamilake in https://github.com/ggerganov/whisper.cpp/pull/605
* Provide option for creating JSON output by @tuxpoldo in https://github.com/ggerganov/whisper.cpp/pull/615
* readme : add react-native bindings by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/619
* Fixed language auto-detection for state provided processing. by @sandrohanea in https://github.com/ggerganov/whisper.cpp/pull/627
* xcodeproj : add `-O3 -DNDEBUG` in release mode by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/640
* Nodejs Addon blocking main thread. Implemented Napi::AsyncWorker by @LucasZNK in https://github.com/ggerganov/whisper.cpp/pull/642
* Include link to R wrapper in README by @jwijffels in https://github.com/ggerganov/whisper.cpp/pull/626
* Add a cmake flag to disable F16C by @a5huynh in https://github.com/ggerganov/whisper.cpp/pull/628
* Add talk-llama example by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/664
* Add Alpaca support to talk-llama example by @ejones in https://github.com/ggerganov/whisper.cpp/pull/668
* Update README.md by @razodactyl in https://github.com/ggerganov/whisper.cpp/pull/682
* issue #470 - working 32-bit ARM by @clach04 in https://github.com/ggerganov/whisper.cpp/pull/486
* whisper : add initial_prompt param by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/645
* fix typo in JSON output by @egorFiNE in https://github.com/ggerganov/whisper.cpp/pull/648
* Fix shell script ./models/download-ggml-model.sh to handle spaces and special characters in paths by @be-next in https://github.com/ggerganov/whisper.cpp/pull/677
* Fixed test to new async implementation by @LucasZNK in https://github.com/ggerganov/whisper.cpp/pull/686
* Minor: fixing usage message for talk-llama by @InconsolableCellist in https://github.com/ggerganov/whisper.cpp/pull/687
* Small typo by @ZiggerZZ in https://github.com/ggerganov/whisper.cpp/pull/688
* feat: add progress callback by @pajowu in https://github.com/ggerganov/whisper.cpp/pull/600
* ggml : fix q4_1 dot product types by @novag in https://github.com/ggerganov/whisper.cpp/pull/759
* Exposed various parts to the Go Interface by @bmurray in https://github.com/ggerganov/whisper.cpp/pull/697
* Adds shell command example for --print-colors by @bocytko in https://github.com/ggerganov/whisper.cpp/pull/710
* Makefile: disable avx in case f16c is not available by @duthils in https://github.com/ggerganov/whisper.cpp/pull/706
* Making the quick start instructions clearer. by @Onlyartist9 in https://github.com/ggerganov/whisper.cpp/pull/716
* Add lrc output support by @WhichWho in https://github.com/ggerganov/whisper.cpp/pull/718
* Corrects default speak.sh path in talk-llama by @mab122 in https://github.com/ggerganov/whisper.cpp/pull/720
* Add msvc compiler args /utf-8 fix error C3688 by @WhichWho in https://github.com/ggerganov/whisper.cpp/pull/721
* Changed convert-pt-to-ggml.py to use .tiktoken tokenizer files by @ivan-gorin in https://github.com/ggerganov/whisper.cpp/pull/725
* talk/talk-llama: add basic example script for eleven-labs tts by @DGdev91 in https://github.com/ggerganov/whisper.cpp/pull/728
* readme : add Unity3d bindings by @Macoron in https://github.com/ggerganov/whisper.cpp/pull/733
* Update stream.cpp by @AliAlameh in https://github.com/ggerganov/whisper.cpp/pull/501
* Fix typos in whisper.h by @GitAritron in https://github.com/ggerganov/whisper.cpp/pull/737
* Update LICENSE by @masguit42 in https://github.com/ggerganov/whisper.cpp/pull/739
* fix potential memory leaks by @baderouaich in https://github.com/ggerganov/whisper.cpp/pull/740
* readme: Add alternate swift bindings by @exPHAT in https://github.com/ggerganov/whisper.cpp/pull/755
* Fix the bug related to word splitting errors in the "tokenize" function. by @AfryMask in https://github.com/ggerganov/whisper.cpp/pull/760
* Do not launch threads for `log_mel_spectrogram` when singlethreaded by @maxilevi in https://github.com/ggerganov/whisper.cpp/pull/763
* Core ML support by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/566
* ggml : fix build on whisper.android (ARM_NEON) by @jhen0409 in https://github.com/ggerganov/whisper.cpp/pull/764
## New Contributors
* @hykelvinlee42 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/552
* @tinoue made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/572
* @venkr made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/569
* @Kamilake made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/605
* @tuxpoldo made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/615
* @jhen0409 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/619
* @LucasZNK made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/642
* @jwijffels made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/626
* @a5huynh made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/628
* @ejones made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/668
* @razodactyl made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/682
* @clach04 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/486
* @egorFiNE made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/648
* @be-next made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/677
* @InconsolableCellist made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/687
* @ZiggerZZ made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/688
* @pajowu made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/600
* @novag made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/759
* @bmurray made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/697
* @bocytko made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/710
* @duthils made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/706
* @Onlyartist9 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/716
* @WhichWho made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/718
* @mab122 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/720
* @ivan-gorin made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/725
* @DGdev91 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/728
* @Macoron made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/733
* @AliAlameh made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/501
* @GitAritron made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/737
* @masguit42 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/739
* @baderouaich made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/740
* @exPHAT made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/755
* @AfryMask made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/760
* @maxilevi made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/763
**Full Changelog**: https://github.com/ggerganov/whisper.cpp/compare/v1.2.1...v1.3.0
## Overview
This is a minor release. The main reason for it is a critical bug fix that causes the software to crash randomly when the language auto-detect option is used (i.e. `whisper_lang_auto_detect()`).
Other than that, the release includes refactoring of the examples, ruby bindings and some minor changes to the C API.
You can provide feedback in the existing [v1.2.0 discussion](https://github.com/ggerganov/whisper.cpp/discussions/467).
## What's Changed
#### Core `ggml` / `whisper`
* `whisper` : whisper : add "split_on_word" flag when using using "max_len" option by @mightymatth in #455 and @boolemancer in https://github.com/ggerganov/whisper.cpp/pull/476
* `whisper` : add whisper_full_lang_id() for getting the context lang by @kamranjon in https://github.com/ggerganov/whisper.cpp/pull/461
* `whisper` : fixed Beam Search Strategy and exposed whisper_pcm_to_mel_phase_vocoder by @sandrohanea in https://github.com/ggerganov/whisper.cpp/pull/474
* `whisper` : suppress non-speech-related token outputs by @shibukazu in https://github.com/ggerganov/whisper.cpp/pull/473
* `cmake` : install whisper.h header by @aviks in https://github.com/ggerganov/whisper.cpp/pull/485
* `whisper` : fix signedness compiler warning by @shikokuchuo in https://github.com/ggerganov/whisper.cpp/pull/506
* `whisper` : by default disable non-speech tokens suppression #473
* `whisper` : add API for applying custom logits filters during decoding 0d229163bbea769c7a3e0e500e45850c9a6e2e42
* `whisper` : fix uninitialized `exp_n_audio_ctx` by @Finnvoor in https://github.com/ggerganov/whisper.cpp/pull/520
#### Bindings
* `bindings` : add Ruby by @taf2 in https://github.com/ggerganov/whisper.cpp/pull/500
* `readme` : add .NET repos (#303)
* `readme` : add cython bindings (#9)
* `readme` : add pybind11 bindings by @aarnphm in https://github.com/ggerganov/whisper.cpp/pull/538
#### Examples
* `ci` : add node addon test and optimize compilation configuration by @chenqianhe in https://github.com/ggerganov/whisper.cpp/pull/468
* `yt-wsp.sh` : add unique filename generation by @genevera in https://github.com/ggerganov/whisper.cpp/pull/495
* `examples` : refactor in order to reuse code and reduce duplication by @ggerganov in https://github.com/ggerganov/whisper.cpp/pull/482
* `main` : fix stdin pipe stream by @conradg in https://github.com/ggerganov/whisper.cpp/pull/503
* `make` : add "-mcpu=native" when building for aarch64 (#532)
#### C-style API
* Add `whisper_pcm_to_mel_phase_vocoder()`
* Add `*(whisper_logits_filter_callback)()`
* Change `struct whisper_full_params`
* Add `whisper_full_lang_id()`
## New Contributors
* @mightymatth made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/455
* @kamranjon made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/461
* @sandrohanea made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/474
* @shibukazu made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/473
* @genevera made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/495
* @shikokuchuo made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/506
* @conradg made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/503
* @taf2 made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/500
* @Finnvoor made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/520
* @aarnphm made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/538
* @FlippFuzz made their first contribution in https://github.com/ggerganov/whisper.cpp/pull/532
**Full Changelog**: https://github.com/ggerganov/whisper.cpp/compare/v1.2.0...v1.2.1
## Highlights
Recently, I have been making progress on adding integer quantisation support in the `ggml` tensor library. This will eventually allow to use quantised models which require less memory and will hopefully run faster. I think the next major release `v1.3.0` will officially add quantisation support. For now, you can keep track of the progress in #540
---
- **🎙️ MacWhisper by @jordibruin powered by whisper.cpp**
https://goodsnooze.gumroad.com/l/macwhisper
<div align="center">
<a href="https://goodsnooze.gumroad.com/l/macwhisper"><img width="1663" alt="image" src="https://user-images.githubusercontent.com/1991296/223670514-5b482ec2-bee3-44c9-b90f-724da750cdf3.png"></a>
</div>