![]()
Zstandard, or zstd as short version, is a fast lossless compression algorithm,
targeting real-time compression scenarios at zlib-level and better compression ratios.
It's backed by a very fast entropy stage, provided by Huff0 and FSE library.
Zstandard's format is stable and documented in RFC8878. Multiple independent implementations are already available.
This repository represents the reference implementation, provided as an open-source dual BSD OR GPLv2 licensed C library,
and a command line utility producing and decoding .zst, .gz, .xz and .lz4 files.
Should your project require another programming language,
a list of known ports and bindings is provided on Zstandard homepage.
Development branch status:




Benchmarks
For reference, several fast compression algorithms were tested and compared
on a desktop featuring a Core i7-9700K CPU @ 4.9GHz
and running Ubuntu 20.04 (Linux ubu20 5.15.0-101-generic),
using lzbench, an open-source in-memory benchmark by @inikep
compiled with gcc 9.4.0,
on the Silesia compression corpus.
| Compressor name | Ratio | Compression | Decompress. |
|---|---|---|---|
| zstd 1.5.6 -1 | 2.887 | 510 MB/s | 1580 MB/s |
| zlib 1.2.11 -1 | 2.743 | 95 MB/s | 400 MB/s |
| brotli 1.0.9 -0 | 2.702 | 395 MB/s | 430 MB/s |
| zstd 1.5.6 --fast=1 | 2.437 | 545 MB/s | 1890 MB/s |
| zstd 1.5.6 --fast=3 | 2.239 | 650 MB/s | 2000 MB/s |
| quicklz 1.5.0 -1 | 2.238 | 525 MB/s | 750 MB/s |
| lzo1x 2.10 -1 | 2.106 | 650 MB/s | 825 MB/s |
| lz4 1.9.4 | 2.101 | 700 MB/s | 4000 MB/s |
| lzf 3.6 -1 | 2.077 | 420 MB/s | 830 MB/s |
| snappy 1.1.9 | 2.073 | 530 MB/s | 1660 MB/s |
The negative compression levels, specified with --fast=#,
offer faster compression and decompression speed
at the cost of compression ratio.
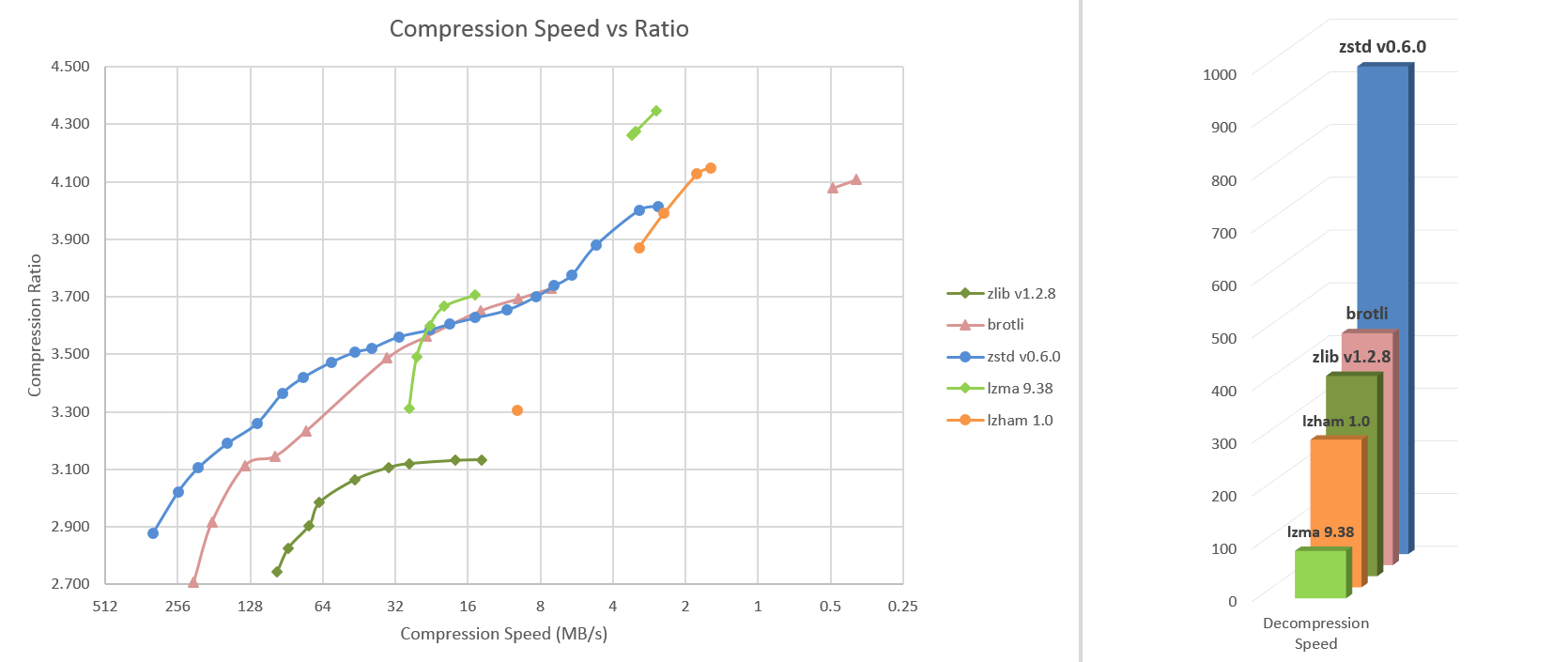
Zstd can also offer stronger compression ratios at the cost of compression speed. Speed vs Compression trade-off is configurable by small increments. Decompression speed is preserved and remains roughly the same at all settings, a property shared by most LZ compression algorithms, such as zlib or lzma.
The following tests were run
on a server running Linux Debian (Linux version 4.14.0-3-amd64)
with a Core i7-6700K CPU @ 4.0GHz,
using lzbench, an open-source in-memory benchmark by @inikep
compiled with gcc 7.3.0,
on the Silesia compression corpus.
| Compression Speed vs Ratio | Decompression Speed |
|---|---|
 |
 |
A few other algorithms can produce higher compression ratios at slower speeds, falling outside of the graph. For a larger picture including slow modes, click on this link.
{kind=link}
The case for Small Data compression
Previous charts provide results applicable to typical file and stream scenarios (several MB). Small data comes with different perspectives.
The smaller the amount of data to compress, the more difficult it is to compress. This problem is common to all compression algorithms, and reason is, compression algorithms learn from past data how to compress future data. But at the beginning of a new data set, there is no "past" to build upon.
To solve this situation, Zstd offers a training mode, which can be used to tune the algorithm for a selected type of data. Training Zstandard is achieved by providing it with a few samples (one file per sample). The result of this training is stored in a file called "dictionary", which must be loaded before compression and decompression. Using this dictionary, the compression ratio achievable on small data improves dramatically.
The following example uses the github-users sample set, created from github public API.
It consists of roughly 10K records weighing about 1KB each.
| Compression Ratio | Compression Speed | Decompression Speed |
|---|---|---|
 |
 |
 |
These compression gains are achieved while simultaneously providing faster compression and decompression speeds.
Training works if there is some correlation in a family of small data samples. The more data-specific a dictionary is, the more efficient it is (there is no universal dictionary). Hence, deploying one dictionary per type of data will provide the greatest benefits. Dictionary gains are mostly effective in the first few KB. Then, the compression algorithm will gradually use previously decoded content to better compress the rest of the file.
Dictionary compression How To:
-
Create the dictionary
zstd --train FullPathToTrainingSet/* -o dictionaryName -
Compress with dictionary
zstd -D dictionaryName FILE -
Decompress with dictionary
zstd -D dictionaryName --decompress FILE.zst
Build instructions
make is the officially maintained build system of this project.
All other build systems are "compatible" and 3rd-party maintained,
they may feature small differences in advanced options.
When your system allows it, prefer using make to build zstd and libzstd.
Makefile
If your system is compatible with standard make (or gmake),
invoking make in root directory will generate zstd cli in root directory.
It will also create libzstd into lib/.
Other available options include:
make install: create and install zstd cli, library and man pagesmake check: create and runzstd, test its behavior on local platform
The Makefile follows the GNU Standard Makefile conventions,
allowing staged install, standard flags, directory variables and command variables.
For advanced use cases, specialized compilation flags which control binary generation
are documented in lib/README.md for the libzstd library
and in programs/README.md for the zstd CLI.
cmake
A cmake project generator is provided within build/cmake.
It can generate Makefiles or other build scripts
to create zstd binary, and libzstd dynamic and static libraries.
By default, CMAKE_BUILD_TYPE is set to Release.
Support for Fat (Universal2) Output
zstd can be built and installed with support for both Apple Silicon (M1/M2) as well as Intel by using CMake's Universal2 support.
To perform a Fat/Universal2 build and install use the following commands:
cmake -B build-cmake-debug -S build/cmake -G Ninja -DCMAKE_OSX_ARCHITECTURES="x86_64;x86_64h;arm64"
cd build-cmake-debug
ninja
sudo ninja install
Meson
A Meson project is provided within build/meson. Follow
build instructions in that directory.
You can also take a look at .travis.yml file for an
example about how Meson is used to build this project.
Note that default build type is release.
VCPKG
You can build and install zstd vcpkg dependency manager:
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install zstd
The zstd port in vcpkg is kept up to date by Microsoft team members and community contributors. If the version is out of date, please create an issue or pull request on the vcpkg repository.
Visual Studio (Windows)
Going into build directory, you will find additional possibilities:
- Projects for Visual Studio 2005, 2008 and 2010.
- VS2010 project is compatible with VS2012, VS2013, VS2015 and VS2017.
- Automated build scripts for Visual compiler by @KrzysFR, in
build/VS_scripts, which will buildzstdcli andlibzstdlibrary without any need to open Visual Studio solution.
Buck
You can build the zstd binary via buck by executing: buck build programs:zstd from the root of the repo.
The output binary will be in buck-out/gen/programs/.
Bazel
You easily can integrate zstd into your Bazel project by using the module hosted on the Bazel Central Repository.
Testing
You can run quick local smoke tests by running make check.
If you can't use make, execute the playTest.sh script from the src/tests directory.
Two env variables $ZSTD_BIN and $DATAGEN_BIN are needed for the test script to locate the zstd and datagen binary.
For information on CI testing, please refer to TESTING.md.
Status
Zstandard is currently deployed within Facebook and many other large cloud infrastructures. It is run continuously to compress large amounts of data in multiple formats and use cases. Zstandard is considered safe for production environments.
License
Zstandard is dual-licensed under BSD OR GPLv2.
Contributing
The dev branch is the one where all contributions are merged before reaching release.
If you plan to propose a patch, please commit into the dev branch, or its own feature branch.
Direct commit to release are not permitted.
For more information, please read CONTRIBUTING.
GitHub
| link |
| Stars: 22410 |
| Last commit: 1 hour ago |
Related Packages
Release Notes
This release highlights the deployment of Google Chrome 123, introducing zstd-encoding for Web traffic, introduced as a preferable option for compression of dynamic contents. With limited web server support for zstd-encoding due to its novelty, we are launching an updated Zstandard version to facilitate broader adoption.
New stable parameter ZSTD_c_targetCBlockSize
Using zstd compression for large documents over the Internet, data is segmented into smaller blocks of up to 128 KB, for incremental updates. This is crucial for applications like Chrome that process parts of documents as they arrive. However, on slow or congested networks, there can be some brief unresponsiveness in the middle of a block transmission, delaying update. To mitigate such scenarios, libzstd introduces the new parameter ZSTD_c_targetCBlockSize, enabling the division of blocks into even smaller segments to enhance initial byte delivery speed. Activating this feature incurs a cost, both runtime (equivalent to -2% speed at level 8) and a slight compression efficiency decrease (<0.1%), but offers some interesting latency reduction, notably beneficial in areas with less powerful network infrastructure.
Granular binary size selection
libzstd provides build customization, including options to compile only the compression or decompression modules, minimizing binary size. Enhanced in v1.5.6 (source), it now allows for even finer control by enabling selective inclusion or exclusion of specific components within these modules. This advancement aids applications needing precise binary size management.
Miscellaneous Enhancements
This release includes various minor enhancements and bug fixes to enhance user experience. Key updates include an expanded list of recognized compressed file suffixes for the --exclude-compressed flag, improving efficiency by skipping presumed incompressible content. Furthermore, compatibility has been broadened to include additional chipsets (sparc64, ARM64EC, risc-v) and operating systems (QNX, AIX, Solaris, HP-UX).
Change Log
api: Promote ZSTD_c_targetCBlockSize to Stable API by @felixhandte
api: new experimental ZSTD_d_maxBlockSize parameter, to reduce streaming decompression memory, by @terrelln
perf: improve performance of param ZSTD_c_targetCBlockSize, by @Cyan4973
perf: improved compression of arrays of integers at high compression, by @Cyan4973
lib: reduce binary size with selective built-time exclusion, by @felixhandte
lib: improved huffman speed on small data and linux kernel, by @terrelln
lib: accept dictionaries with partial literal tables, by @terrelln
lib: fix CCtx size estimation with external sequence producer, by @embg
lib: fix corner case decoder behaviors, by @Cyan4973 and @aimuz
lib: fix zdict prototype mismatch in static_only mode, by @ldv-alt
lib: fix several bugs in magicless-format decoding, by @embg
cli: add common compressed file types to --exclude-compressed by @daniellerozenblit (requested by @dcog989)
cli: fix mixing -c and -o commands with --rm, by @Cyan4973
cli: fix erroneous exclusion of hidden files with --output-dir-mirror by @felixhandte
cli: improved time accuracy on BSD, by @felixhandte
cli: better errors on argument parsing, by @KapJI
tests: better compatibility with older versions of grep, by @Cyan4973
tests: lorem ipsum generator as default content generator, by @Cyan4973
build: cmake improvements by @terrelln, @sighingnow, @gjasny, @JohanMabille, @Saverio976, @gruenich, @teo-tsirpanis
build: bazel support, by @jondo2010
build: fix cross-compiling for AArch64 with lld by @jcelerier
build: fix Apple platform compatibility, by @nidhijaju
build: fix Visual 2012 and lower compatibility, by @Cyan4973
build: improve win32 support, by @DimitriPapadopoulos
build: better C90 compliance for zlibWrapper, by @emaste
port: make: fat binaries on macos, by @mredig
port: ARM64EC compatibility for Windows, by @dunhor
port: QNX support by @klausholstjacobsen
port: MSYS2 and Cygwin makefile installation and test support, by @QBos07
port: risc-v support validation in CI, by @Cyan4973
port: sparc64 support validation in CI, by @Cyan4973
port: AIX compatibility, by @likema
port: HP-UX compatibility, by @likema
doc: Improved specification accuracy, by @elasota
bug: Fix and deprecate ZSTD_generateSequences (#3981), by @terrelln
Full change list (auto-generated)
- Add win32 to windows-artifacts.yml by @Kim-SSi in https://github.com/facebook/zstd/pull/3600
- Fix mmap-dict help output by @daniellerozenblit in https://github.com/facebook/zstd/pull/3601
- [oss-fuzz] Fix simple_round_trip fuzzer with overlapping decompression by @terrelln in https://github.com/facebook/zstd/pull/3612
- Reduce streaming decompression memory by (128KB - blockSizeMax) by @terrelln in https://github.com/facebook/zstd/pull/3616
- removed travis & appveyor scripts by @Cyan4973 in https://github.com/facebook/zstd/pull/3621
- Add ZSTD_d_maxBlockSize parameter by @terrelln in https://github.com/facebook/zstd/pull/3617
- [doc] add decoder errata paragraph by @Cyan4973 in https://github.com/facebook/zstd/pull/3620
- add makefile entry to build fat binary on macos by @mredig in https://github.com/facebook/zstd/pull/3614
- Disable unused variable warning in msan configurations by @danlark1 in https://github.com/facebook/zstd/pull/3624 https://github.com/facebook/zstd/pull/3634
- Allow Build-Time Exclusion of Individual Compression Strategies by @felixhandte in https://github.com/facebook/zstd/pull/3623
- Get zstd working with ARM64EC on Windows by @dunhor in https://github.com/facebook/zstd/pull/3636
- minor : update streaming_compression example by @Cyan4973 in https://github.com/facebook/zstd/pull/3631
- Fix UBSAN issue (zero addition to NULL) by @terrelln in https://github.com/facebook/zstd/pull/3658
- Add options in Makefile to cmake by @sighingnow in https://github.com/facebook/zstd/pull/3657
- fix a minor inefficiency in compress_superblock by @Cyan4973 in https://github.com/facebook/zstd/pull/3668
- Fixed a bug in the educational decoder by @Cyan4973 in https://github.com/facebook/zstd/pull/3659
- changed LLU suffix into ULL for Visual 2012 and lower by @Cyan4973 in https://github.com/facebook/zstd/pull/3664
- fixed decoder behavior when nbSeqs==0 is encoded using 2 bytes by @Cyan4973 in https://github.com/facebook/zstd/pull/3669
- detect extraneous bytes in the Sequences section by @Cyan4973 in https://github.com/facebook/zstd/pull/3674
- Bitstream produces only zeroes after an overflow event by @Cyan4973 in https://github.com/facebook/zstd/pull/3676
- Update FreeBSD CI images to latest supported releases by @emaste in https://github.com/facebook/zstd/pull/3684
- Clean up a false error message in the LDM debug log by @embg in https://github.com/facebook/zstd/pull/3686
- Hide ASM symbols on Apple platforms by @nidhijaju in https://github.com/facebook/zstd/pull/3688
- Changed the decoding loop to detect more invalid cases of corruption sooner by @Cyan4973 in https://github.com/facebook/zstd/pull/3677
- Fix Intel Xcode builds with assembly by @gjasny in https://github.com/facebook/zstd/pull/3665
- Save one byte on the frame epilogue by @Coder-256 in https://github.com/facebook/zstd/pull/3700
- Update fileio.c: fix build failure with enabled LTO by @LocutusOfBorg in https://github.com/facebook/zstd/pull/3695
- fileio_asyncio: handle malloc fails in AIO_ReadPool_create by @void0red in https://github.com/facebook/zstd/pull/3704
- Fix typographical error in README.md by @nikohoffren in https://github.com/facebook/zstd/pull/3701
- Fixed typo by @alexsifivetw in https://github.com/facebook/zstd/pull/3712
- Improve dual license wording in README by @terrelln in https://github.com/facebook/zstd/pull/3718
- Unpoison Workspace Memory Before Custom-Free by @felixhandte in https://github.com/facebook/zstd/pull/3725
- added ZSTD_decompressDCtx() benchmark option to fullbench by @Cyan4973 in https://github.com/facebook/zstd/pull/3726
- No longer reject dictionaries with literals maxSymbolValue < 255 by @terrelln in https://github.com/facebook/zstd/pull/3731
- fix: ZSTD_BUILD_DECOMPRESSION message by @0o001 in https://github.com/facebook/zstd/pull/3728
- Updated Makefiles for full MSYS2 and Cygwin installation and testing … by @QBos07 in https://github.com/facebook/zstd/pull/3720
- Work around nullptr-with-nonzero-offset warning by @terrelln in https://github.com/facebook/zstd/pull/3738
- Fix & refactor Huffman repeat tables for dictionaries by @terrelln in https://github.com/facebook/zstd/pull/3737
- zdictlib: fix prototype mismatch by @ldv-alt in https://github.com/facebook/zstd/pull/3733
- Fixed zstd cmake shared build on windows by @JohanMabille in https://github.com/facebook/zstd/pull/3739
- Added qnx in the posix test section of platform.h by @klausholstjacobsen in https://github.com/facebook/zstd/pull/3745
- added some documentation on ZSTD_estimate*Size() variants by @Cyan4973 in https://github.com/facebook/zstd/pull/3755
- Improve macro guards for ZSTD_assertValidSequence by @terrelln in https://github.com/facebook/zstd/pull/3770
- Stop suppressing pointer-overflow UBSAN errors by @terrelln in https://github.com/facebook/zstd/pull/3776
- fix x32 tests on Github CI by @Cyan4973 in https://github.com/facebook/zstd/pull/3777
- Fix new typos found by codespell by @DimitriPapadopoulos in https://github.com/facebook/zstd/pull/3771
- Do not test WIN32, instead test _WIN32 by @DimitriPapadopoulos in https://github.com/facebook/zstd/pull/3772
- Fix a very small formatting typo in the lib/README.md file by @dloidolt in https://github.com/facebook/zstd/pull/3763
- Fix pzstd Makefile to allow setting
DESTDIRandBINDIRseparately by @paulmenzel in https://github.com/facebook/zstd/pull/3752 - Remove FlexArray pattern from ZSTDMT by @Cyan4973 in https://github.com/facebook/zstd/pull/3786
- solving flexArray issue #3785 in fse by @Cyan4973 in https://github.com/facebook/zstd/pull/3789
- Add doc on how to use it with cmake FetchContent by @Saverio976 in https://github.com/facebook/zstd/pull/3795
- Correct FSE probability bit consumption in specification by @elasota in https://github.com/facebook/zstd/pull/3806
- Add Bazel module instructions to README.md by @jondo2010 in https://github.com/facebook/zstd/pull/3812
- Clarify that a stream containing too many Huffman weights is invalid by @elasota in https://github.com/facebook/zstd/pull/3813
- [cmake] Require CMake version 3.5 or newer by @gruenich in https://github.com/facebook/zstd/pull/3807
- Three fixes for the Linux kernel by @terrelln in https://github.com/facebook/zstd/pull/3822
- [huf] Improve fast huffman decoding speed in linux kernel by @terrelln in https://github.com/facebook/zstd/pull/3826
- [huf] Improve fast C & ASM performance on small data by @terrelln in https://github.com/facebook/zstd/pull/3827
- update xxhash library to v0.8.2 by @Cyan4973 in https://github.com/facebook/zstd/pull/3820
- Modernize macros to use
do { } while (0)by @terrelln in https://github.com/facebook/zstd/pull/3831 - Clarify that the presence of weight value 1 is required, and a lone implied 1 weight is invalid by @elasota in https://github.com/facebook/zstd/pull/3814
- Move offload API params into ZSTD_CCtx_params by @embg in https://github.com/facebook/zstd/pull/3839
- Update FreeBSD CI: drop 12.4 (nearly EOL) by @emaste in https://github.com/facebook/zstd/pull/3845
- Make offload API compatible with static CCtx by @embg in https://github.com/facebook/zstd/pull/3854
- zlibWrapper: convert to C89 / ANSI C by @emaste in https://github.com/facebook/zstd/pull/3846
- Fix a nullptr dereference in ZSTD_createCDict_advanced2() by @michoecho in https://github.com/facebook/zstd/pull/3847
- Cirrus-CI: Add FreeBSD 14 by @emaste in https://github.com/facebook/zstd/pull/3855
- CI: meson: use builtin handling for MSVC by @eli-schwartz in https://github.com/facebook/zstd/pull/3858
- cli: better errors on argument parsing by @KapJI in https://github.com/facebook/zstd/pull/3850
- Clarify that probability tables must not contain non-zero probabilities for invalid values by @elasota in https://github.com/facebook/zstd/pull/3817
- [x-compile] Fix cross-compiling for AArch64 with lld by @jcelerier in https://github.com/facebook/zstd/pull/3760
- playTests.sh does no longer needs grep -E by @Cyan4973 in https://github.com/facebook/zstd/pull/3865
- minor: playTests.sh more compatible with older versions of grep by @Cyan4973 in https://github.com/facebook/zstd/pull/3877
- disable Intel CET Compatibility tests by @Cyan4973 in https://github.com/facebook/zstd/pull/3884
- improve cmake test by @Cyan4973 in https://github.com/facebook/zstd/pull/3883
- add sparc64 compilation test by @Cyan4973 in https://github.com/facebook/zstd/pull/3886
- add a lorem ipsum generator by @Cyan4973 in https://github.com/facebook/zstd/pull/3890
- Update Dependency in Intel CET Test; Re-Enable Test by @felixhandte in https://github.com/facebook/zstd/pull/3893
- Improve compression of Arrays of Integers (High compression mode) by @Cyan4973 in https://github.com/facebook/zstd/pull/3895
- [Zstd] Less verbose log for patch mode. by @sandreenko in https://github.com/facebook/zstd/pull/3899
- fix 5921623844651008 by @Cyan4973 in https://github.com/facebook/zstd/pull/3900
- Fix fuzz issue 5131069967892480 by @Cyan4973 in https://github.com/facebook/zstd/pull/3902
- Advertise Availability of Security Vulnerability Notifications by @felixhandte in https://github.com/facebook/zstd/pull/3909
- updated setup-msys2 to v2.22.0 by @Cyan4973 in https://github.com/facebook/zstd/pull/3914
- Lorem Ipsum generator update by @Cyan4973 in https://github.com/facebook/zstd/pull/3913
- Reduce scope of variables by @gruenich in https://github.com/facebook/zstd/pull/3903
- Improve speed of ZSTD_c_targetCBlockSize by @Cyan4973 in https://github.com/facebook/zstd/pull/3915
- More regular block sizes with
targetCBlockSizeby @Cyan4973 in https://github.com/facebook/zstd/pull/3917 - removed sprintf usage from zstdcli.c by @Cyan4973 in https://github.com/facebook/zstd/pull/3916
- Export a
zstd::libzstdCMake target if only static or dynamic linkage is specified. by @teo-tsirpanis in https://github.com/facebook/zstd/pull/3811 - fix version of actions/checkout by @Cyan4973 in https://github.com/facebook/zstd/pull/3926
- minor Makefile refactoring by @Cyan4973 in https://github.com/facebook/zstd/pull/3753
- lib/decompress: check for reserved bit corruption in zstd by @aimuz in https://github.com/facebook/zstd/pull/3840
- Fix state table formatting by @elasota in https://github.com/facebook/zstd/pull/3816
- Specify offset 0 as invalid and specify required fixup behavior by @elasota in https://github.com/facebook/zstd/pull/3824
- update -V documentation by @Cyan4973 in https://github.com/facebook/zstd/pull/3928
- fix LLU->ULL by @Cyan4973 in https://github.com/facebook/zstd/pull/3929
- Fix building xxhash on AIX 5.1 by @likema in https://github.com/facebook/zstd/pull/3860
- Fix building on HP-UX 11.11 PA-RISC by @likema in https://github.com/facebook/zstd/pull/3862
- Fix AsyncIO reading seed queueing by @yoniko in https://github.com/facebook/zstd/pull/3940
- Use ZSTD_LEGACY_SUPPORT=5 in "make test" by @embg in https://github.com/facebook/zstd/pull/3943
- Pin sanitizer CI jobs to ubuntu-20.04 by @embg in https://github.com/facebook/zstd/pull/3945
- chore: fix some typos by @acceptacross in https://github.com/facebook/zstd/pull/3949
- new method to deal with offset==0 erroneous edge case by @Cyan4973 in https://github.com/facebook/zstd/pull/3937
- add tests inspired from #2927 by @Cyan4973 in https://github.com/facebook/zstd/pull/3948
- cmake refactor: move HP-UX specific logic into its own function by @Cyan4973 in https://github.com/facebook/zstd/pull/3946
- Fix #3719 : mixing -c, -o and --rm by @Cyan4973 in https://github.com/facebook/zstd/pull/3942
- minor: fix incorrect debug level by @Cyan4973 in https://github.com/facebook/zstd/pull/3936
- add RISC-V emulation tests to Github CI by @Cyan4973 in https://github.com/facebook/zstd/pull/3934
- prevent XXH64 from being autovectorized by XXH512 by default by @Cyan4973 in https://github.com/facebook/zstd/pull/3933
- Stop Hardcoding the POSIX Version on BSDs by @felixhandte in https://github.com/facebook/zstd/pull/3952
- Convert the CircleCI workflow to a GitHub Actions workflow by @jk0 in https://github.com/facebook/zstd/pull/3901
- Add common compressed file types to --exclude-compressed by @daniellerozenblit in https://github.com/facebook/zstd/pull/3951
- Export ZSTD_LEGACY_SUPPORT in tests/Makefile by @embg in https://github.com/facebook/zstd/pull/3955
- Exercise ZSTD_findDecompressedSize() in the simple decompression fuzzer by @embg in https://github.com/facebook/zstd/pull/3959
- Update
ZSTD_RowFindBestMatchcomment by @yoniko in https://github.com/facebook/zstd/pull/3947 - Add the zeroSeq sample by @Cyan4973 in https://github.com/facebook/zstd/pull/3954
- [cpu] Backport fix for rbx clobbering on Windows with Clang by @terrelln in https://github.com/facebook/zstd/pull/3957
- Do not truncate file name in verbose mode by @Cyan4973 in https://github.com/facebook/zstd/pull/3956
- updated documentation by @Cyan4973 in https://github.com/facebook/zstd/pull/3958
- [asm][aarch64] Mark that BTI and PAC are supported by @terrelln in https://github.com/facebook/zstd/pull/3961
- Use
utimensat()on FreeBSD by @felixhandte in https://github.com/facebook/zstd/pull/3960 - reduce the amount of #include in cover.h by @Cyan4973 in https://github.com/facebook/zstd/pull/3962
- Remove Erroneous Exclusion of Hidden Files and Folders in
--output-dir-mirrorby @felixhandte in https://github.com/facebook/zstd/pull/3963 - Promote
ZSTD_c_targetCBlockSizeParameter to Stable API by @felixhandte in https://github.com/facebook/zstd/pull/3964 - [cmake] Always create libzstd target by @terrelln in https://github.com/facebook/zstd/pull/3965
- Remove incorrect docs regarding ZSTD_findFrameCompressedSize() by @embg in https://github.com/facebook/zstd/pull/3967
- add line number to debug traces by @Cyan4973 in https://github.com/facebook/zstd/pull/3966
- bump version number by @Cyan4973 in https://github.com/facebook/zstd/pull/3969
- Export zstd's public headers via BUILD_INTERFACE by @terrelln in https://github.com/facebook/zstd/pull/3968
- Fix bug with streaming decompression of magicless format by @embg in https://github.com/facebook/zstd/pull/3971
- pzstd: use c++14 without conditions by @kanavin in https://github.com/facebook/zstd/pull/3682
- Fix bugs in simple decompression fuzzer by @yoniko in https://github.com/facebook/zstd/pull/3978
- Fuzzing and bugfixes for magicless-format decoding by @embg in https://github.com/facebook/zstd/pull/3976
- Fix & fuzz ZSTD_generateSequences by @terrelln in https://github.com/facebook/zstd/pull/3981
- Fail on errors when building fuzzers by @yoniko in https://github.com/facebook/zstd/pull/3979
- [cmake] Emit warnings for contradictory build settings by @terrelln in https://github.com/facebook/zstd/pull/3975
- Document the process for adding a new fuzzer by @embg in https://github.com/facebook/zstd/pull/3982
- Fix -Werror=pointer-arith in fuzzers by @embg in https://github.com/facebook/zstd/pull/3983
- Doc update by @Cyan4973 in https://github.com/facebook/zstd/pull/3977
- v1.5.6 by @Cyan4973 in https://github.com/facebook/zstd/pull/3984
New Contributors
- @Kim-SSi made their first contribution in https://github.com/facebook/zstd/pull/3600
- @mredig made their first contribution in https://github.com/facebook/zstd/pull/3614
- @dunhor made their first contribution in https://github.com/facebook/zstd/pull/3636
- @sighingnow made their first contribution in https://github.com/facebook/zstd/pull/3657
- @nidhijaju made their first contribution in https://github.com/facebook/zstd/pull/3688
- @gjasny made their first contribution in https://github.com/facebook/zstd/pull/3665
- @Coder-256 made their first contribution in https://github.com/facebook/zstd/pull/3700
- @LocutusOfBorg made their first contribution in https://github.com/facebook/zstd/pull/3695
- @void0red made their first contribution in https://github.com/facebook/zstd/pull/3704
- @nikohoffren made their first contribution in https://github.com/facebook/zstd/pull/3701
- @alexsifivetw made their first contribution in https://github.com/facebook/zstd/pull/3712
- @0o001 made their first contribution in https://github.com/facebook/zstd/pull/3728
- @QBos07 made their first contribution in https://github.com/facebook/zstd/pull/3720
- @JohanMabille made their first contribution in https://github.com/facebook/zstd/pull/3739
- @klausholstjacobsen made their first contribution in https://github.com/facebook/zstd/pull/3745
- @Saverio976 made their first contribution in https://github.com/facebook/zstd/pull/3795
- @elasota made their first contribution in https://github.com/facebook/zstd/pull/3806
- @jondo2010 made their first contribution in https://github.com/facebook/zstd/pull/3812
- @gruenich made their first contribution in https://github.com/facebook/zstd/pull/3807
- @michoecho made their first contribution in https://github.com/facebook/zstd/pull/3847
- @KapJI made their first contribution in https://github.com/facebook/zstd/pull/3850
- @jcelerier made their first contribution in https://github.com/facebook/zstd/pull/3760
- @sandreenko made their first contribution in https://github.com/facebook/zstd/pull/3899
- @teo-tsirpanis made their first contribution in https://github.com/facebook/zstd/pull/3811
- @aimuz made their first contribution in https://github.com/facebook/zstd/pull/3840
- @acceptacross made their first contribution in https://github.com/facebook/zstd/pull/3949
- @jk0 made their first contribution in https://github.com/facebook/zstd/pull/3901
Full Changelog: https://github.com/facebook/zstd/compare/v1.5.5...v1.5.6
Swiftpack is being maintained by Petr Pavlik | @ptrpavlik | @swiftpackco | API | Analytics