SwiftNodes


![]()
![]()
👩🏻🚀 This project is still a tad experimental. Contributors and pioneers welcome!
What?
SwiftNodes offers a concurrency safe graph data structure together with graph algorithms. A graph stores values in identifiable nodes which can be connected via edges.
Contents
Why?
Graphs may be the most fundamental mathematical concept besides numbers. They have wide applications in problem solving, data analysis and visualization. And although such data structures fit well with the language, graph implementations in Swift are lacking – in particular, comprehensive graph algorithm libraries.
SwiftNodes and its included algorithms were extracted from Codeface. But SwiftNodes is general enough to serve other applications as well – and extensible enough for more algorithms to be added.
Design Goals
- Usability, safety, extensibility and maintainability – which also imply simplicity.
- In particular, the API is supposed to feel familiar and fit well with official Swift data structures. So one question that guides its design is: What would Apple do?
We put the above qualities over performance. But that doesn't mean we neccessarily end up with suboptimal performance. The main compromise SwiftNodes involves is that nodes are value types and can not be referenced, so they must be hashed. But that doesn't change the average case complexity and, in the future, we might even be able to avoid that hashing in essential use cases by exploiting array indices.
How?
This section is a tutorial and touches only parts of the SwiftNodes API. We recommend exploring the DocC reference, unit tests and production code. The code in particular is actually small, meaninfully organized and easy to grasp.
Understand and Initialize Graphs
Let's look at our first graph:
let graph = Graph<Int, Int, Double>(values: [1, 2, 3], // values serve as node IDs
edges: [(1, 2), (2, 3), (1, 3)])
Graph is generic over three types: Graph<NodeID: Hashable, NodeValue, EdgeWeight: Numeric>. Much like a Dictionary stores values for unique keys, a Graph stores values for unique node IDs. Actually, the Graph stores the values within its nodes which we identify by their IDs. Unlike a Dictionary, a Graph also allows to connect its unique "value locations", which are its node IDs. Those connections are the graph's edges, and each of them has a numeric weight.
So, in the above example, Graph<Int, Int, Double> stores Int values for Int node IDs and connects these node IDs (nodes) through edges that each have a Double weight. We provided the values and specified the edges. But where do the actual Int node IDs and Double edge weights come from? In both regards, the above initializer is a rather convenient one that infers things:
- When values and node IDs are of the same (and thereby hashable) type, SwiftNodes infers that we actually don't need distinct node IDs, so each unique value also serves as the ID of its own node.
- When we don't want to use or specify edge weights, we can specify edges by just the node IDs they connect, and SwiftNodes will create the corresponding edges with a default weight of 1.
We could explicitly provide distinct node IDs, for example of type String:
let graph = Graph<String, Int, Double>(valuesByID: ["a": 1, "b": 2, "c": 3],
edges: [("a", "b"), ("b", "c"), ("a", "c")])
And if we want to add all edges later, we can create graphs without edges via array- and dictionary literals:
let graph = Graph<Int, Int, Double> = [1, 2, 3] // values serve as node IDs
_ = Graph<String, Int, Double> = ["a": 1, "b": 2, "c": 3]
In two of the above examples (1st and 3rd graph), SwiftNodes can infer node IDs because node values are of the same type. There is one other type of value with which we don't need to provide node IDs: node values that are Identifiable by the same type of ID as nodes are, i.e. NodeID == NodeValue.ID. In that case, each value's unique ID also serves as the ID of the value's node. This does not work with array literals but with initializers:
struct IdentifiableValue: Identifiable { let id = UUID() }
typealias IVGraph = Graph<UUID, IdentifiableValue, Double>
let values = [IdentifiableValue(), IdentifiableValue(), IdentifiableValue()]
let ids = values.map { $0.id }
let graph = IVGraph(values: values, // value IDs serve as node IDs
edges: [(ids[0], ids[1]), (ids[1], ids[2]), (ids[0], ids[2])])
For all initializer variants see Graph.swift and Graph+ConvenientInitializers.swift.
Values
Just like with a Dictionary, you can read, write and delete values via subscripts and via functions:
var graph = Graph<String, Int, Double>()
graph["a"] = 1
let valueA = graph["a"]
graph["a"] = nil
graph.update(2, for: "b") // returns the updated/created `Node` as `@discardableResult`
let valueB = graph.value(for: "b")
graph.removeValue(for: "b") // returns the removed `NodeValue?` as `@discardableResult`
let allValues = graph.values // returns `some Collection`
And just like with the graph initializers, you don't need to provide node IDs if either the values themselves or their IDs can serve as node IDs. Here, values are identical to their node IDs:
var graph = Graph<Int, Int, Double>()
graph.insert(1) // returns the updated/created `Node` as `@discardableResult`
graph.remove(1) // returns the removed `Node?` as `@discardableResult`
Edges
Each edge is identified by the two nodes it connects, thus an edge ID is a combination of two node IDs. Edges are also directed, which means they point in a direction, from one node to another, which we might call "origin-" and "destination node" (or similar). Directed edges are the most general form. If a client or algorithm works with "undirected" graphs, that simply means it doesn't care about edge direction.
The three basic operations are inserting, reading and removing edges:
var graph: Graph<Int, Int, Double> = [1, 2, 3] // values serve as node IDs
graph.insertEdge(from: 1, to: 2) // returns the edge as `@discardableResult`
let edge = graph.edge(from: 1, to: 2) // the optional edge itself
let hasEdge = graph.containsEdge(from: 1, to: 2) // whether the edge exists
graph.removeEdge(from: 1, to: 2) // returns the optional edge as `@discardableResult`
Of course, Graph also has properties providing all edges, all edges by their IDs and all edge IDs. And it has ways to initialize and mutate edge weights. For the whole edge API, see Graph.swift and Graph+EdgeAccess.swift.
Nodes
Nodes are basically identifiable value containers that can be connected by edges. But aside from values they also store the IDs of neighbouring nodes. This redundant storage (cache) is kept up to date by the Graph and makes graph traversal a bit more performant and convenient. Any given node has these cache-based properties:
node.descendantIDs // IDs of all nodes to which there is an edge from node
node.ancestorIDs // IDs of all nodes from which there is an edge to node
node.neighbourIDs // all descendant- and ancestor IDs
node.isSink // whether node has no descendants
node.isSource // whether node has no ancestors
For the whole node API, see Graph.swift and Graph+NodeAccess.swift.
Marking Nodes
Many graph algorithms do associate little intermediate results with individual nodes. The literature often refers to this as "marking" a node. The most prominent example is marking a node as visited while traversing a potentially cyclic graph. Some algorithms write multiple different markings to nodes.
When we made SwiftNodes concurrency safe (to play well with the new Swift concurrency features), we removed the possibility to mark nodes directly, as that had lost its potential for performance optimization. See how the included algorithms now use hashing to associate markings with nodes.
Value Semantics and Concurrency
Like official Swift data structures, Graph is a pure struct and inherits the benefits of value types:
- You decide on mutability by using
varorlet. - You can use a
Graphas a@Stateor@Publishedvariable with SwiftUI. - You can use property observers like
didSetto observe changes in aGraph. - You can easily copy a whole
Graph.
Many algorithms produce a variant of a given graph. Rather than modifying the original graph, SwiftNodes suggests to copy it, and you can copy a Graph like any other value.
A Graph is also Sendable if its value- and id type are. SwiftNodes is thereby ready for the strict concurrency safety of Swift 6. You can safely share Sendable Graph values between actors. Remember that, to declare a Graph property on a Sendable reference type, you need to make that property constant (use let).
Included Algorithms
SwiftNodes has begun to accumulate some graph algorithms. The following overview also links to Wikipedia articles that explain what the algorithms do. We recommend also exploring them in code.
Filter and Map
You can map graph values and filter graphs by values, edges and nodes. Of course, the filters keep edges and node neighbour caches consistent and produce proper subgraphs.
let graph: Graph<Int, Int, Int> = [1, 2, 10, 20]
let oneDigitGraph = graph.filtered { $0 < 10 }
let stringGraph = graph.map { "\($0)" }
See all filters in Graph+FilterAndMap.swift.
Components
graph.findComponents() returns multiple sets of node IDs which represent the components of the graph.
Strongly Connected Components
graph.findStronglyConnectedComponents() returns multiple sets of node IDs which represent the strongly connected components of the graph.
Condensation Graph
graph.makeCondensationGraph() creates the condensation graph of the graph, which is the graph in which all strongly connected components of the original graph have been collapsed into single nodes, so the resulting condensation graph is acyclic.
Transitive Reduction
graph.findTransitiveReductionEdges() finds all edges of the transitive reduction (the minimum equivalent graph) of the graph. You can also use filterTransitiveReduction() and filteredTransitiveReduction() to create a graph's minimum equivalent graph.
Right now, all this only works on acyclic graphs and might even hang or crash on cyclic ones.
Essential Edges
graph.findEssentialEdges() returns the IDs of all "essential" edges. You can also use graph.filterEssentialEdges() and graph.filteredEssentialEdges() to remove all "non-essential" edges from a graph.
Edges are essential when they correspond to edges of the MEG (the transitive reduction) of the condensation graph. In simpler terms: Essential edges are either in cycles or they are essential to the reachability described by the graph – i.e. they cannot be removed without destroying the only path between some nodes.
Note that only edges of the condensation graph can be non-essential and so edges in cycles (i.e. in strongly connected components) are all considered essential. This is because it's algorithmically as well as conceptually hard to decide which edges in cycles are "non-essential". We recommend dealing with cycles independently of using this function.
Ancestor Counts
graph.findNumberOfNodeAncestors() returns a Dictionary<NodeID, Int> containing the ancestor count for each node ID of the graph. The ancestor count is the number of all (recursive) ancestors of the node. Basically, it's the number of other nodes from which the node can be reached.
This only works on acyclic graphs right now and might return incorrect results for nodes in cycles.
Ancestor counts can serve as a proxy for topological sorting.
Architecture
Here is the architecture (composition and essential dependencies) of the SwiftNodes code folder:
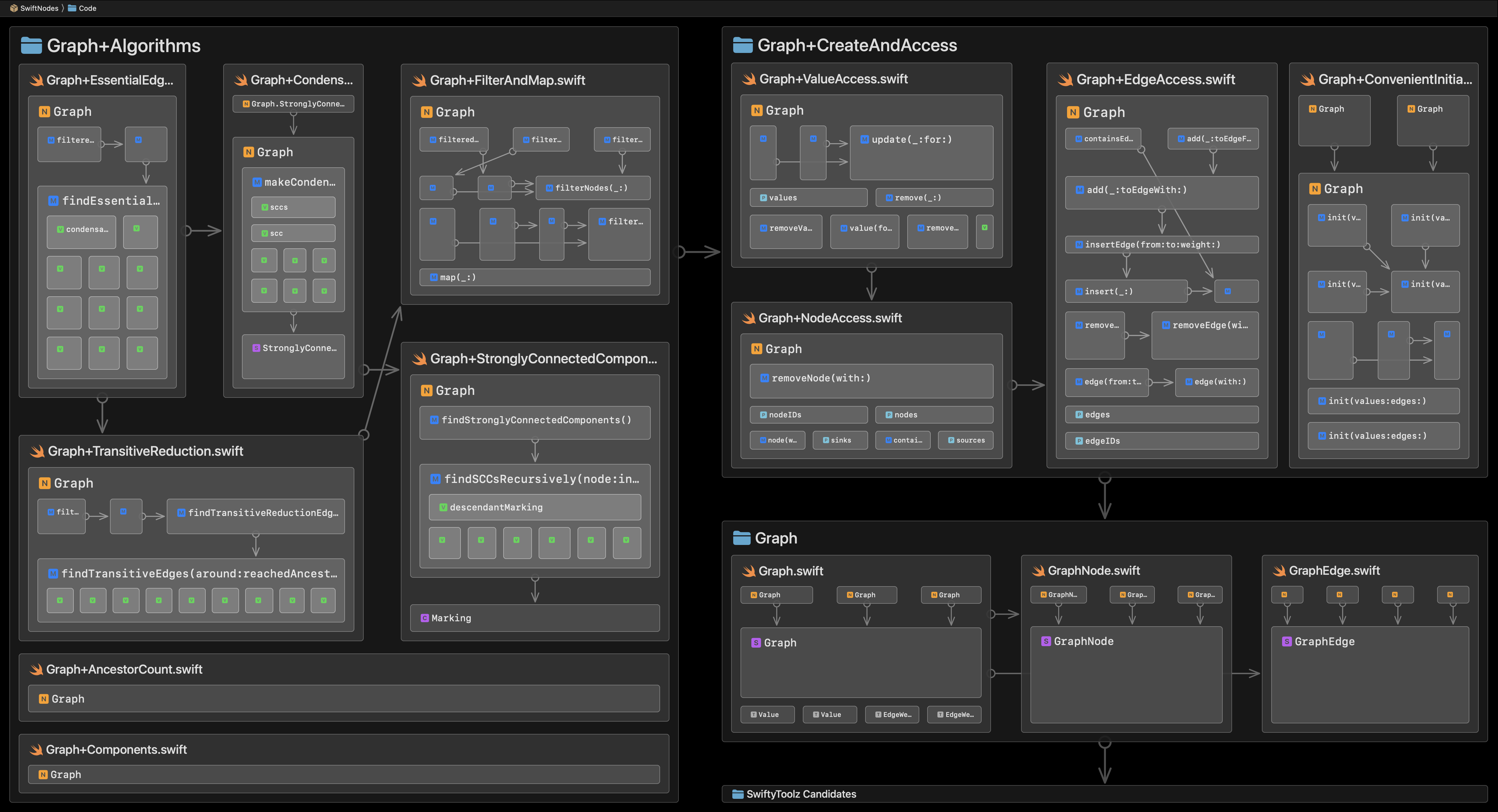
The above image was created with Codeface.
Development Status
From version/tag 0.1.0 on, SwiftNodes adheres to semantic versioning. So until it has reached 1.0.0, its API may still break frequently, and we express those breaks with minor version bumps.
SwiftNodes is already being used in production, but Codeface is still its primary client. SwiftNodes will move to version 1.0.0 as soon as either one of these conditions is met:
- Basic practicality and conceptual soundness have been validated by serving multiple real-world clients.
- We feel it's mature enough (well rounded and stable API, comprehensive tests, complete documentation and solid achievement of design goals).
Roadmap
- Review, update and complete all documentation, including API comments
- Review tests again and add more to cover the API comprehensively
- Round out and add algorithms (starting with the needs of Codeface):
- Make existing algorithms compatible with cycles (two algorithms are still not). meaning: don't hang or crash, maybe throw an error!
- Move to version 1.0.0 if possible
- Add general purpose graph traversal algorithms (BFT, DFT, compatible with potentially cyclic graphs)
- Add better ways of topological sorting
- Approximate the minimum feedback arc set, so Codeface can guess "faulty" or unintended dependencies, i.e. the fewest dependencies that need to be cut in order to break all cycles.
- Possibly optimize performance – but only based on measurements and only if measurements show that the optimization yields significant acceleration. Optimizing the algorithms might be more effective than optimizing the data structure itself.
- What role can
@inlinableplay here? - What role can
lazyplay here?
- What role can
GitHub
| link |
| Stars: 28 |
| Last commit: 43 weeks ago |
Dependencies
Release Notes
This update turns the former edge count into a proper generically typed edge weight, whereby Graph and GraphEdge each gain another type parameter. This, of course, is a breaking change, and all tests had to be adjusted.
Swiftpack is being maintained by Petr Pavlik | @ptrpavlik | @swiftpackco | API | Analytics